Go 语言学习笔记
声明
变量
单变量声明
1 | //声明类型,另行赋值 |
多变量声明
1 | //声明同个类型,非全局变量 |
数组
唯一类型,长度固定,已编号的序列。
数组长度是数组type的一部分。
数组最大长度为 2Gb。
索引超出数组长度时,会 panic。
单维数组声明
1 | //指定元素类型及个数 |
初始化数组:
1 | //声明时赋值,{}数据量不能大于[] |
多维数组
1 | var arr_name [SIZE1][SIZE2]...[SIZEN] arr_type |
注意: 如果要用变量来代表构成二维数组的长度:
1 | //这是不对的! |
二维数组初始化:
1 | a = [3][4]int{ |
数组操作
- 用 for 遍历:
1
2
3for i:=0; i < len(arr1); i++{
arr1[i] = ...
} - 用 for-range:
1
for i,_:= range arr1 {...}
- new() 的区别:故传参时,
1
2var arr1 = new([5]int) // arr1 的类型是 *[5]int
var arr2 [5]int // arr2 的类型是 [5]intfunc1(arr2)是数组拷贝,不能修改原数组。要修改,要func(&arr2) - 把大数组传给函数会消耗很多内存,避免方法:(1)传递数组的指针;(2)使用数组的切片。
切片
是对数组一个连续片段的引用(该数组称为相关数组,通常是匿名的)。
切片声明
1 | //声明类型,省略大小 |
new() 和 make() 的区别:
- new(T) 为每个新的类型T分配一片内存,初始化为 0 并且返回类型为T的内存地址:这种方法*返回一个指向类型为 T,值为 0 的地址的指针**,它适用于值类型如数组和结构体。
- make(T) 返回一个类型为 T 的初始值,它只适用于3种内建的引用类型:切片、map 和 channel。
即 new 函数分配内存,make 函数初始化。 - 切片初始化:*
1
2
3
4
5
6//直接:=声明+初始化
s := []int{1,2,3} // cap = len = 3
//用数组初始化切片
s := arr[:] // s := arr[startIndex:endIndex]
var s []type arr[:] - 空(nil)切片:*
一个切片在未初始化之前默认为 nil,长度为 0。1
2
3
4var s []int
if(s == nil){
...
}切片的操作
- 切片重组(reslice):切片达到cao上限后可扩容,改变切片长度的过程称为重组reslicing。做法:
slice1 = slice1[0:end]
切片扩展 1 位:sl = sl[0:len(sl)+1] - 切片后移 1 位:
s = s[1:],不可前移。 - 注意:不要用指针指向 slice,因为切片本身已经是一个引用类型,所以它本身就是一个指针!
- for-range 用于切片时,第一个返回值 ix 是索引,第二个返回值 val 是该索引位置的值,val 是值拷贝。
copy(sl_to, sl_form)切片复制apend(sl, elem1...)切片追加- s 是个字符串(本质是字节数组),那可通过
c := []byte(s)来获得字节切片 c。或者copy(dst []byte, src string) - 字符串是不可被赋值修改的,要修改可以将字符串转化成字节数字,然后修改数组元素,最后把字节数组转换回字符串:
1
2
3
4s := "hello"
c := []byte(s)
c[0] = 'c'
s2 := string(c) // s2 == "cello" sort包实现搜索和排序。搜索元素前必须先排序(因为搜索是二分法)。sort 官方文档1
2
3
4
5
6sort.Ints(arri) // 升序排序
func Float64s(a []float64)
func Stirings(a []string)
IntsAreSorted(a []int) bool // 检查是否已被排序
func SearchInts(a []int, n int) int // 搜索- append 函数常见操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 切片 b 追加到切片 a 之后:
a = append(a, b...)
// 复制切片 a 的元素到新的切片 b 上:
b = make([]T, len(a))
copy(b, a)
// 删除位于索引 i 的元素:
a = append(a[:i], a[i+1:]...)
// 切除切片 a 中从索引 i 至 j 位置的元素:
a = apend(a[:i], a[j:]...)
// 为切片 a 拓展 j 个元素长度:
a = append(a, make([]T, j)...)
// 在索引 i 的位置插入元素 x:
a = append(a[:i], append([]T{x}, a[i:]...)...)
// 在索引 i 的位置插入切片 b 的所有元素:
a = append(a[:i], append(b, a[i:]...)...)
// 取出位于切片 a 最末尾的元素 x:
x, a = a[len(a)-1], a[:len(a)-1]
切片和垃圾回收
切片的底层是数组,数组实际容量可能大于切片容量,只有没有任何切片指向数组时,底层数组的内存才会被释放,因此可能对导致过多内存被占用。
指针
指针声明
1 | var p_name *p_type |
指针使用:
1 | var a int = 20 |
空指针:
1 | var ptr *int |
数组指针
1 | package main |
输出结果:
1 | a[0] = 10 |
结构体
一系列相同或不同类型的数据结构构成的集合。
组成结构体类型的数据称为字段(field)。
定义结构体
1 | //定义结构体 |
结构体指针
1 | //定义指向结构体的指针 |
使用工厂方法创建结构体实例
1 | type File struct { //定义了如下的 File 结构体类型 |
如果想知道结构体类型T的一个实例占用了多少内存,可以使用:size := unsafe.Sizeof(T{})。
试图 make() 一个结构体变量,会引发一个编译错误,这还不是太糟糕,但是 new() 一个映射并试图使用数据填充它,将会引发运行时错误! 因为 new(Foo) 返回的是一个指向 nil 的指针,它尚未被分配内存。所以在使用 map 时要特别谨慎。:
1 | type Foo map[string]string |
带标签的结构体
结构体中的字段除了有名字和类型外,还可以有一个可选的标签(tag):它是一个附属于字段的字符串,可以是文档或其他的重要标记。标签的内容不可以在一般的编程中使用,只有包 reflect 能获取它。 reflect包可以在运行时自省类型、属性和方法,比如:在一个变量上调用 reflect.TypeOf() 可以获取变量的正确类型,如果变量是一个结构体类型,就可以通过 Field 来索引结构体的字段,然后就可以使用 Tag 属性。
1 | import ( |
匿名字段和内嵌结构体
结构体可以包含一个或多个 匿名(或内嵌)字段,即这些字段没有显式的名字,只有字段的类型是必须的,此时类型就是字段的名字。匿名字段本身可以是一个结构体类型,即 结构体可以包含内嵌结构体。
- 当两个字段命名冲突时候:
- 外场名字会覆盖内层名字(但是两者的内存空间都保留),这提供了一种重载字段或方法的方式;
- 如果相同的名字在同一级别出现了两次,如果这个名字被程序使用了,将会引发一个错误(不使用没关系)。没有办法来解决这种问题引起的二义性,必须由程序员自己修正。
方法
Go 方法是作用在接收者(receiver)上的一个函数,接收者是某种类型的变量。因此方法是一种特殊类型的函数。
接收者类型可以是(几乎)任何类型,不仅仅是结构体类型:任何类型都可以有方法,甚至可以是函数类型,可以是 int、bool、string 或数组的别名类型。但是接收者不能是一个接口类型,因为接口是一个抽象定义,但是方法却是具体实现;如果这样做会引发一个编译错误:invalid receiver type…。
最后接收者不能是一个指针类型,但是它可以是任何其他允许类型的指针。
一个类型加上它的方法等价于面向对象中的一个类。一个重要的区别是:在 Go 中,类型的代码和绑定在它上面的方法的代码可以不放置在一起,它们可以存在在不同的源文件,唯一的要求是:它们必须是同一个包的。
类型 T(或 T)上的所有方法的集合叫做类型 T(或 T)的方法集**。
定义方法的一般格式:
1 | func (recv receiver_type) methodName(parameter_list) (return_value_list) { ... } |
在方法名之前,func 关键字之后的括号中指定 receiver。
如果 recv 是 receiver 的实例,Method1 是它的方法名,那么方法调用遵循传统的 object.name 选择器符号:recv.Method1()。
如果 recv 是一个指针,Go 会自动解引用。
函数和方法的区别
函数将变量作为参数:Function1(recv)
方法在变量上被调用:recv.Method1()
receiver_type 叫做 (接收者)基本类型,这个类型必须在和方法同样的包中被声明。
方法没有和数据定义(结构体)混在一起:它们是正交的类型;表示(数据)和行为(方法)是独立的。
方法和未导出字段
内嵌类型的方法和继承
将父类型放在子类型中来实现亚型。
The way to Go 参考内容
在类型中嵌入功能
主要有两种方法来实现在类型中嵌入功能:
A:聚合(或组合):包含一个所需功能类型的具名字段。
B:内嵌:内嵌(匿名地)所需功能类型。
多重继承
和其他面向对象语言比较 Go 的类型和方法
在如 C++、Java、C# 和 Ruby 这样的面向对象语言中,方法在类的上下文中被定义和继承:在一个对象上调用方法时,运行时会检测类以及它的超类中是否有此方法的定义,如果没有会导致异常发生。
在 Go 语言中,这样的继承层次是完全没必要的:如果方法在此类型定义了,就可以调用它,和其他类型上是否存在这个方法没有关系。在这个意义上,Go 具有更大的灵活性。
Go 不需要一个显式的类定义,如同 Java、C++、C# 等那样,相反地,“类”是通过提供一组作用于一个共同类型的方法集来隐式定义的。类型可以是结构体或者任何用户自定义类型。
总结
在 Go 中,类型就是类(数据和关联的方法)。Go 不知道类似面向对象语言的类继承的概念。继承有两个好处:代码复用和多态。
在 Go 中,代码复用通过组合和委托实现,多态通过接口的使用来实现:有时这也叫 组件编程(Component Programming)。
许多开发者说相比于类继承,Go 的接口提供了更强大、却更简单的多态行为。
备注
如果真的需要更多面向对象的能力,看一下 goop 包(Go Object-Oriented Programming),它由 Scott Pakin 编写: 它给 Go 提供了 JavaScript 风格的对象(基于原型的对象),并且支持多重继承和类型独立分派,通过它可以实现你喜欢的其他编程语言里的一些结构。
类型的 String() 方法和格式化描述符
如果类型定义了 String() 方法,它会被用在 fmt.Printf() 中生成默认的输出:等同于使用格式化描述符 %v 产生的输出。还有 fmt.Print() 和 fmt.Println() 也会自动使用 String() 方法。
格式化描述符 %T 会给出类型的完全规格,%#v 会给出实例的完整输出,包括它的字段(在程序自动生成 Go 代码时也很有用)。
备注
不要在 String() 方法里面调用涉及 String() 方法的方法,它会导致意料之外的错误,比如下面的例子,它导致了一个无限递归调用(TT.String() 调用 fmt.Sprintf,而 fmt.Sprintf 又会反过来调用 TT.String()…),很快就会导致内存溢出:
1 | type TT float64 |
Map(集合)
一种无序的键值的集合。可以迭代,不返回顺序。
通过key来快速检索。
声明时不需要知道 map 长度,map 可以动态增长。不存在固定长度或最大限制,但可以选择表明map的初始容量 capacity:make(map[keytype]valuetype, cap)
未初始化的 map 的值是 nil。
1 | //变量声明,不初始化的话,默认map是nil,nil map不能用来存放键值 |
Map的基本操作
测试键值对
1
2
3
4
5_, ok := map1[key1] // 如果key1存在则ok == true,否则ok为false
if _, ok := map1[key1]; ok {
// ...
}delete()函数
删除Map的元素,参数为key。1
2delete(map1, key1) // 如果 key1 不存在,该操作不会产生错误。
delete(countryCapitalMap, "France")for-range 用法
1
2
3for key, value := range map1 {
...
}
用切片作为 map 的值
1 | mp1 := make(map[int][]int) |
map 类型的切片
必须用两次 make(),第一次分配切片,第二次分配切片中每个 map 元素:
1 | func main() { |
注意,应当像 A 版本那样通过索引使用切片的 map 元素。在 B 版本中获得的项只是 map 值的一个拷贝而已,所以真正的 map 元素没有得到初始化。
map 的排序
map 默认是无序的。
如要排序,要将 key(或 value)拷贝到一个切片,在对切片排序(sort 包),然后用切片的 for-range 方法打印 key 和 value。
1 | var ( |
如果想要一个排序的列表,最好使用结构体切片,这样更有效:
1 | type name struct { |
指针
1 | s := "Hello World!" |
为了防止内存溢出,Go 语言不允许指针算法(如: pointer+2),因此 c = *p++ 是非法的。
接口(Interfaces)与反射(reflection)
接口提供了一种方式来 说明 对象的行为:如果谁能搞定这件事,它就可以用在这儿。
接口定义了一组方法(方法集),但不包含(实现)代码:它们没有被实现(它们是抽象的)。接口里也不能包含变量。
定义接口的格式:
1 | type Namer interface{ // namer 是一个接口类型 |
按约定,只包含一个方法的接口的名字由方法名加 [e]r 后缀组成,如 Printer、Reader、Writer、Logger、Converter 等。
类型(如结构体)实现接口方法集中的方法,每个方法的实现说明了次方法是如何作用于该类型的: 即实现接口,同时方法集也构成了该类型的接口。
类型不需要显式声明它实现了某个接口:接口被隐式地实现。多个类型可以实现同一个接口。
实现某个接口的类型(除了实现接口方法外)可以有其他的方法。
一个类型可以实现多个接口。
接口类型可以包含一个实例的引用, 该实例的类型实现了此接口(接口是动态类型)。
即使接口在类型之后才定义,二者处于不同的包中,被单独编译:只要类型实现了接口中的方法,它就实现了此接口。
所有这些特性使得接口具有很大的灵活性。
1 | package main |
这是 多态 的 Go 版本,多态是面向对象编程中一个广为人知的概念:根据当前的类型选择正确的方法,或者说:同一种类型在不同的实例上似乎表现出不同的行为。
1 | package main |
接口嵌套接口
一个接口可以包含一个或多个其他的接口,这相当于直接将这些内嵌接口的方法列举在外层接口中一样:
1 | type ReadWrite interface { |
类型断言:如何检测和转换接口变量的类型
一个接口类型的变量 varI 中可以包含任何类型的值,必须有一种方式来检测它的 动态 类型,即运行时在变量中存储的值的实际类型。通常我们可以使用 类型断言 来测试在某个时刻 varI 是否包含类型 T 的值:
1 | v := varI.(T) // unchecked type assertion |
varI 必须是一个接口变量,否则编译器会报错:invalid type assertion: varI.(T) (non-interface type (type of varI) on left) 。
类型断言可能是无效的,更安全的方式是使用以下形式来进行类型断言:
1 | if v, ok := varI.(T); ok { // checked type assertion |
如果转换合法,v 是 varI 转换到类型 T 的值,ok 会是 true;
否则 v 是类型 T 的零值,ok 是 false,也没有运行时错误(panic)发生。
1 | func main() { |
应该总是使用上面的方式来进行类型断言。
1 | package main |
类型判断(选择):type-switch
类型选择中的声明与类型断言 i.(T) 的语法相同,只是具体类型 T 被替换成了关键字 type。
接口变量的类型也可以使用一种特殊形式的 switch 来检测:type-switch :
eg1:
1 | switch t := areaIntf.(type) { |
输出:
1 | Type Square *main.Square with value &{5} |
eg2:
1 | func do(i interface{}) { |
输出:
1 | Twice 21 is 42 |
变量 t 得到了 areaIntf 的值和类型, 所有 case 语句中列举的类型(nil 除外)都必须实现对应的接口(在上例中即 Shaper),如果被检测类型没有在 case 语句列举的类型中,就会执行 default 语句。
可以用 type-switch 进行运行时类型分析,但是在 type-switch 不允许有 fallthrough 。
如果仅仅是测试变量的类型,不用它的值,那么就可以不需要赋值语句,比如:
1 | switch areaIntf.(type) { |
下面的代码片段展示了一个类型分类函数,它有一个可变长度参数,可以是任意类型的数组,它会根据数组元素的实际类型执行不同的动作:
1 | func classifier(items ...interface{}) { |
可以这样调用此方法:classifier(13, -14.3, "BELGIUM", complex(1, 2), nil, false) 。
在处理来自于外部的、类型未知的数据时,比如解析诸如 JSON 或 XML 编码的数据,类型测试和转换会非常有用。
测试一个值是否实现了某个接口
假定 v 是一个值,然后我们想测试它是否实现了 Stringer 接口,可以这样做:
1 | type Stringer interface { |
接口是一种契约,实现类型必须满足它,它描述了类型的行为,规定类型可以做什么。接口彻底将类型能做什么,以及如何做分离开来,使得相同接口的变量在不同的时刻表现出不同的行为,这就是多态的本质。
编写参数是接口变量的函数,这使得它们更具有一般性。
使用接口使代码更具有普适性。
使用方法集与接口
作用于变量上的方法实际上是不区分变量到底是指针还是值的。当碰到接口类型值时,这会变得有点复杂,原因是接口变量中存储的具体值是不可寻址的,幸运的是,如果使用不当编译器会给出错误。
总结
在接口上调用方法时,必须有和方法定义时相同的接收者类型或者是可以从具体类型 P 直接可以辨识的:
- 指针方法可以通过指针调用
- 值方法可以通过值调用
- 接收者是值的方法可以通过指针调用,因为指针会首先被解引用
- 接收者是指针的方法不可以通过值调用,因为存储在接口中的值没有地址
将一个值赋值给一个接口时,编译器会确保所有可能的接口方法都可以在此值上被调用,因此不正确的赋值在编译期就会失败。
译注
Go 语言规范定义了接口方法集的调用规则:
- 类型 *T 的可调用方法集包含接受者为 *T 或 T 的所有方法集
- 类型 T 的可调用方法集包含接受者为 T 的所有方法
- 类型 T 的可调用方法集不包含接受者为 *T 的方法
第一个例子:使用 Sorter 接口排序
第二个例子:读和写
io 包提供了用于读和写的接口 io.Reader 和 io.Writer:
1 | type Reader interface { |
一个对象要是可读的,它必须实现 io.Reader 接口,这个接口只有一个签名是 Read(p []byte) (n int, err error) 的方法,它从调用它的对象上读取数据,并把读到的数据放入参数中的字节切片中,然后返回读取的字节数和一个 error 对象,如果没有错误发生返回 nil,如果已经到达输入的尾端,会返回 io.EOF("EOF"),如果读取的过程中发生了错误,就会返回具体的错误信息。类似地,一个对象要是可写的,它必须实现 io.Writer 接口,这个接口也只有一个签名是 Write(p []byte) (n int, err error) 的方法,它将指定字节切片中的数据写入调用它的对象里,然后返回实际写入的字节数和一个 error 对象(如果没有错误发生就是 nil)。
io 包里的 Readers 和 Writers 都是不带缓冲的,bufio 包里提供了对应的带缓冲的操作,在读写 UTF-8 编码的文本文件时它们尤其有用。
空接口
空接口或者最小接口 不包含任何方法,它对实现不做任何要求:
1 | type Any interface {} |
任何其他类型都实现了空接口,any 或 Any 是空接口一个很好的别名或缩写。
可以给一个空接口类型的变量 var val interface {} 赋任何类型的值。
1 | package main |
空接口在 type-switch 中联合 lambda 函数的用法:
1 | package main |
构建通用类型或包含不同类型变量的数组
通过使用空接口。让我们给空接口定一个别名类型 Element:type Element interface{}
然后定义一个容器类型的结构体 Vector,它包含一个 Element 类型元素的切片:
1 | type Vector struct { |
Vector 里能放任何类型的变量,因为任何类型都实现了空接口,实际上 Vector 里放的每个元素可以是不同类型的变量。我们为它定义一个 At() 方法用于返回第 i 个元素:
1 | func (p *Vector) At(i int) Element { |
再定一个 Set() 方法用于设置第 i 个元素的值:
1 | func (p *Vector) Set(i int, e Element) { |
Vector 中存储的所有元素都是 Element 类型,要得到它们的原始类型(unboxing:拆箱)需要用到类型断言。
复制数据切片至空接口切片
假设你有一个 myType 类型的数据切片,你想将切片中的数据复制到一个空接口切片中,必须使用 for-range 语句来一个一个显式地复制:
1 | var dataSlice []myType = FuncReturnSlice() |
通用类型的节点数据结构
[The way to Go 参考内容](https://github.com/Unknwon/the-way-to-go_ZH_CN/blob/master/eBook/11.9.md#1194-%E9%80%9A%E7%94%A8%E7%B1%BB%E5%9E%8B%E7%9A%84%E8%8A%82%E7%82%B9%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84)
接口到接口
[The way to Go 参考内容](https://github.com/Unknwon/the-way-to-go_ZH_CN/blob/master/eBook/11.9.md#1195-%E6%8E%A5%E5%8F%A3%E5%88%B0%E6%8E%A5%E5%8F%A3)
反射包
反射是用程序检查其所拥有的结构,尤其是类型的一种能力;这是元编程的一种形式。反射可以在运行时检查类型和变量,例如它的大小、方法和 动态
的调用这些方法。这对于没有源代码的包尤其有用。这是一个强大的工具,除非真得有必要,否则应当避免使用或小心使用。
变量的最基本信息就是类型和值:反射包的 Type 用来表示一个 Go 类型,反射包的 Value 为 Go 值提供了反射接口。
实际上,反射是通过检查一个接口的值,变量首先被转换成空接口:
1 | func TypeOf(i interface{}) Type |
reflect.Type 和 reflect.Value 都有许多方法用于检查和操作它们。一个重要的例子是 Value 有一个 Type 方法返回 reflect.Value 的 Type。另一个是 Type 和 Value 都有 Kind 方法返回一个常量来表示类型:Uint、Float64、Slice 等等。同样 Value 有叫做 Int 和 Float 的方法可以获取存储在内部的值(跟 int64 和 float64 一样)
1 | const ( |
对于 float64 类型的变量 x,如果 v:=reflect.ValueOf(x),那么 v.Kind() 返回 reflect.Float64 ,所以下面的表达式是 truev.Kind() == reflect.Float64
1 | // Kind 总是返回底层类型: |
变量 v 的 Interface() 方法可以得到还原(接口)值,所以可以这样打印 v 的值:fmt.Println(v.Interface())
eg.
1 | func main() { |
通过反射修改(设置)值:
假设我们要把 x 的值改为 3.1415。Value 有一些方法可以完成这个任务,但是必须小心使用:v.SetFloat(3.1415)。
这将产生一个错误:reflect.Value.SetFloat using unaddressable value。
问题的原因是 v 不是可设置的(这里并不是说值不可寻址)。是否可设置是 Value 的一个属性,并且不是所有的反射值都有这个属性:可以使用 CanSet() 方法测试是否可设置。
在例子中我们看到 v.CanSet() 返回 false: settability of v: false
当 v := reflect.ValueOf(x) 函数通过传递一个 x 拷贝创建了 v,那么 v 的改变并不能更改原始的 x。要想 v 的更改能作用到 x,那就必须传递 x 的地址 v = reflect.ValueOf(&x)。
通过 Type() 我们看到 v 现在的类型是 *float64 并且仍然是不可设置的。
要想让其可设置我们需要使用 Elem() 函数,这间接的使用指针:v = v.Elem()
现在 v.CanSet() 返回 true 并且 v.SetFloat(3.1415) 设置成功了!
eg.
1 | func main() { |
反射中有些内容是需要用地址去改变它的状态的。
反射结构:
有些时候需要反射一个结构类型。NumField() 方法返回结构内的字段数量;通过一个 for 循环用索引取得每个字段的值 Field(i)。
我们同样能够调用签名在结构上的方法,例如,使用索引 n 来调用:Method(n).Call(nil)。
eg.
1 | type NotknownType struct { |
但是如果尝试更改一个值,会得到一个错误:
1 | panic: reflect.Value.SetString using value obtained using unexported field |
这是因为结构中只有被导出字段(首字母大写)才是可设置的
eg2.
1 | type T struct { |
Printf 和反射
接口与动态类型
总结:Go 中的面向对象
Go 没有类,而是松耦合的类型、方法对接口的实现。
OO 语言最重要的三个方面分别是:封装,继承和多态,在 Go 中它们是怎样表现的呢?
封装(数据隐藏):和别的 OO 语言有 4 个或更多的访问层次相比,Go 把它简化为了 2 层(参见 4.2 节的可见性规则):
1)包范围内的:通过标识符首字母小写,
对象只在它所在的包内可见2)可导出的:通过标识符首字母大写,
对象对所在包以外也可见
类型只拥有自己所在包中定义的方法。
- 继承:用组合实现:内嵌一个(或多个)包含想要的行为(字段和方法)的类型;多重继承可以通过内嵌多个类型实现
- 多态:用接口实现:某个类型的实例可以赋给它所实现的任意接口类型的变量。类型和接口是松耦合的,并且多重继承可以通过实现多个接口实现。Go 接口不是 Java 和 C# 接口的变体,而且接口间是不相关的,并且是大规模编程和可适应的演进型设计的关键。
常用包
strings 包
Go 中使用 strings 包对字符串进行操作。
前、后缀
HasPrefix 判断字符串 s 是否以 prefix 开头:
1 | strings.HasPrefix(s, prefix string) bool |
HasSuffix 判断字符串 s 是否以 suffix 结尾:
1 | strings.HasSuffix(s, suffix string) bool |
字符串包含关系
Contains 判断字符串 s 是否包含 substr :
1 | strings.Contains(s, substr string) bool |
索引字符串位置
Index 返回字符串 str 在字符串 s 中的第一次出现的索引(str 的第一个字符的索引),
返回 -1 表示 s 不包含 str:
1 | strings.Index(s, str string) int |
LastIndex 返回 str 在 s 中最后出现的所有(第一个字符),
返回 -1 表示 s 不包含 str:
1 | strings.LastIndex(s, str string) int |
建议用 IndexRune 查询非 ASCII 编码的字符在字符串中的位置(返回 -1 表示 s 不包含 str: ):
1 | strings.IndexRune(s string, r rune) int |
字符串替换
Replace 用于将字符串 str 中的前 n 个字符串 old 替换为字符串 new,并范围一个新的字符串,如果 n = -1 啧替换所有有 old 为 new:
1 | strings.Replace(str, old, new, n) string |
统计字符串出现的次数
Count 用于统计字符串 str 中字符串 s 出现的非重叠次数:
1 | strings.Count(s, str string) int |
重复字符串
Repeat 用于重复 count 次字符串 s 并返回一个新的字符串:
1 | strings.Repeat(s, count int) string |
修改字符串大小写
ToLower 讲字符串中的 Unicode 字符全部转换为相应的小写字符:
1 | strings.Tolower(s) string |
ToUpper 讲字符串中的 Unicode 字符全部转换为相应的大写字符:
1 | strings.ToUpper(s) string |
修剪字符串
strings.TrimSpace(s) 用于剔除字符串开头和结尾的空白符号;strings.Trim(s, "cut") 用于剔除字符串开头和结尾的 cut;TrimLeft 或者 TrimRight 用于只剔除开头或结尾的字符串。
分割字符串
strings.Fields(s) 会利用 1 个或多个空白符号来作为动态长度的分隔符将字符串分割成若干小块,并返回一个 slice,如果字符串只包含空白符号,则返回一个长度为 0 的 slice。strings.Split(s, sep) 用于自定义分割符号来对指定字符串进行分割,同样范围 slice。
因为这 2 个函数都会返回 slice,所以习惯使用 for - range 循环来对其进行处理。
拼接 slice 到字符串
Join 用于将元素类型为 string 的 slice 使用分割符号来拼接组成一个字符串:
1 | strings.Join(sl [string], sep string) string |
从字符串中读取内容
strings.NewReader(str) 用于生成一个 ‘Reader’ 并读取字符串中的内容,然后返回指向该 Reader 的指针,从其他类型读取内容的函数还有:Read 从 []byte 中读取内容;ReadByte() 和 ReadRune() 从字符串中读取下一个 byte 或者 rune。
Strconv 包
与字符串相关的类型转换。
包含了一些变量用于获取程序运行的操作系统平台下 int 类型所占的位数,如:strconv.IntSize。
任何类型 T 转换为字符串总是成功的。
数字 → 字符串:
strconv.Itoa(i int) string返回数字 i 所表示的字符串类型的十进制数。strconv.FormatFloat(f float64, fmt byte, prec int, bitSize int) string将64位浮点型数字转换为字符串,其中fmt表示格式(其值可以是b、e、f或g),prec表示精度,bitSize则使用 32 表示 float32,用 64 表示 float64。
将字符串转换为其他类型 tp 并不总是可能的,可能会在运行时抛出错误 parsing "…": invalid argument。
字符串 → 数字类型:
strconv.Atoi(s string) (i int, err error)将字符串转换为 int 型。strconv.ParseFloat(s string, bitSize int) (f float64, err error)将字符串转换为 float64 型。
利用多个返回值的特性(第 1 个是转换后的结果(若成功),第 2 个是可能出现的错误),一般使用如下形式进行从字符串到其它类型的转换:
1 | val, err = strconv.Atoi(s) |
time 包:时间和日期
time 包提供了一个数据类型 time.Time(作为值使用)以及显示和测量时间和日期的功能函数。
获取当前时间:time.Now();
1 | var t time.Time = time.Now() |
获取时间的一部分: t.Day、t.Minute()…
自定义时间格式化字符串:eg.fmt.Printf("%02d.%02d.%4d\n", t.Day(), t.Month(), t.Year()) 将会输出 08.03.2019
Duration 类型表示两个连续时刻所相差的纳秒数,类型为 int64。Location 类型映射某个时区的时间,UTC 表示通用协调世界时间。
包中的一个预定义函数 func (t Time) Format(layout string) string 可以根据一个格式化字符串来将一个t转换为相应格式的字符串,你可以使用一些预定义的格式,如:time.ANSIC 或 time.RFC822。
1 | fmt.Println((t.Format("02 Jan 2006 15:04"))) |
如果需要在应用程序在经过一定时间或周期执行某项任务(事件处理的特例),则可以使用 time.After 或者 time.Ticker。
另外,time.Sleep(Duration d) 可以实现对某个进程(实质上是 goroutine)时长为 d 的暂停。
其他关于时间操作的文档参考 官方文档 或 国内访问页面。
控制结构
if-else 结构
1 | // if |
一些例子:
- 判断一个字符串是否为空:
if str == "" {...}if len(str) == 0 {...}
- 判断运行 Go 程序的操作系统类型,这可以通过常量
runtime.GOOS来判断。这段代码一般被放在 init() 函数中执行。 如以下示例演示如何根据操作系统来决定输入结束时的提示:1
2
3
4
5if runtime.GOOS == "windows" {
...
} else {
...
}1
2
3
4
5
6
7
8var prompt = "Enter a digit, e.g. 3 "+ "or %s to quit."
func init() {
if runtime.GOOS == "windows" {
prompt = fmt.Sprintf(prompt, "Ctrl+Z, Enter")
} else { // Unix-like
prompt = fmt.Sprintf(prompt, "Ctrl+D")
}
} - 函数
Abs()用于返回一个整型数字的绝对值:1
2
3
4
5
6func Abs(x int) int {
if x < 0 {
return -x
}
return x
} isGrater用来比较两个整型数字的大小:if 可以包含一个初始化语句(如:给变量赋值),初始化语句后方必须加分号:1
2
3
4
5
6func isGreater(x,y int) bool {
if x > y {
return true
}
return false
}注意1
2
3if val := 10; val > max {
// do something
}:=声明的变量作用于仅在 if 结构中。如果变量在 if 结构之前就已经存在,那么在 if 结构中该变量原来的值会被隐藏。comma,ok模式(pattern)
Go 语言中函数经常用两个返回值来表示是否执行成功:返回某个值以及 true 表示成功;返回零值(或 nil)和 false 表示失败。也可以使用 error 类型的变量来代替第二个返回值:成功执行的话,error 的值为 nil,否则就会包含相应的错误信息。
习惯用法
1 | value, err := pack1.Function1(param1) |
如果要在错误发生的同时终止程序的运行,可以使用 os 包的 Exit 函数:
1 | if err != nil { |
当没有错误发生时,代码继续运行就是唯一要做的事情,所以 if 语句块后面不需要使用 else 分支。
switch 结构
1 | switch var1 { |
- 测试多个可能符合条件的值,使用逗号分隔,例如:
case val1, val2, val3。 - 每个
case分支都是唯一的,从上至下逐一测试,直到匹配为止。 - 一旦成功匹配某个分支,在执行完相应代码后就会退出整个 switch 代码块,所以不用
break。 - 如果执行完
case后还需要继续执行后续分支的代码,要使用fallthrough。 - 可以用
return语句来提前结束代码块的执行。(还要时刻确保函数始终有返回值,switch 后再添加相应return) switch后也可不跟变量,case后跟 condition,用起来像链式 if-else。switch后也可跟一个初始化语句,需要加分号;。
for 结构
计数器形式
基本形式:
1 | for 初始化语句; 条件语句; 修饰语句 {} |
- 特别注意,永远不要在循环体内修改计数器!
同时使用多个计数器:
1 | for i, j := 0, N; i < j; i, j = i+1, j-1 {} |
条件判断的迭代形式
基本形式:for 条件语句 {}
无限循环
基本形式:for {}
- 需要循环内用
break或return退出循环体。(break只是退出循环体,return是提前对函数进行返回,不会执行后续代码) - 无限循环的经典应用是服务器,用于不断等待和接受新的请求:
1
2
3for t, err = p.Token(); err == nil; t, err = p.Token() {
...
}for-range 结构
用于迭代任何一个集合(数组、map)。
一般形式:for ix, val := range coll {...} - 需要注意,val始终是集合中索引的值的拷贝,对它修改不会影响集合内原值(除非
val为指针)。 - 一个字符串是 Unicode 编码的字符(或称之为
rune)集合,因此可可以用它迭代字符串:1
2
3for pos, char := range str {
...
}Break 与 continue
- 一个 break 的作用范围是该语句出现后的最内部的结构。(只会跳出最内层循环)
- 关键词 continue 忽略剩余循环体直接进入下一次循环过程,执行下次循环前需要判断循环条件。
- continue 只能用于 for 循环中。
标签与 goto
- 标签名称是大小写敏感的,一般建议全用大写字母。
- 配合 goto 跳出多层循环或模拟循环。
- 不鼓励使用标签和 goto,会导致糟糕的程序设计,可被更可读的方案替代。
- 一定要用的话,只使用正序的标签(先 goto,后标签),且两者间不能出现新的定义变量语句!
函数
- Go 中不允许函数重载(function overloading,指可以编写多个同名函数)。
- 如果需要声明一个在外部定义的函数,只要给出函数名与函数签名,不用给出函数体:
1
func flushICache(begin, end uintptr) // implemented externally
- 函数可以被作为类型来声明使用:
1
type binOp func(int, int) int
传参和返回
- 分按值传递(call by value) 按引用传递(call by reference)。
- 几乎在任何情况下,传递指针的消耗比传递副本来的少。
- 在函数调用时,像切片(slice)、字典(map)、接口(interface)、通道(channel)这样的引用类型都是默认使用引用传递(即使没有显式的指出指针)。
- 如果函数要返回四到五个值,可以传递一个切片给函数(如果返回值具有相同类型)或者是传递一个结构体(如果返回值具有不同的类型)。因为传递一个指针允许直接修改变量的值,消耗也更少。
传递变长参数
- 变参函数:函数最有一个参数采用
...type的形式。函数接受某个类型的 slice 的参数。1
func myFunc(a, b, arg ...int) {}
- 解决边长参数不是相同类型的方法:(1)使用结构;(2)使用空接口。
defer 和追踪
- 关键词 defer 让我们推迟到函数返回之前(或任意位置执行
return语句之后)一刻才执行某个语句或函数。 - defer 一般用于释放某些已分配的资源。
- 多个 defer 行为被注册,会逆序执行(类似栈),
- defer 允许我们进行一些函数执行完成后的收尾工作:(1)关闭文件流;(2)解锁一个加锁的资源;(3)打印最终报告;(4)关闭数据库连接。
- 用 defer 实现代码追踪。
- 用 defer 记录函数的参数与返回值。
内置函数
不需要导入就可使用。
| 名称 | 说明 |
|---|---|
| close | 用于管道通信 |
| len、cap len | 用于返回某个类型的长度或数量(字符串、数组、切片、map 和管道);cap 是容量的意思,用于返回某个类型的最大容量(只能用于切片和 map) |
| new、make | new 和 make 均是用于分配内存:new 用于值类型和用户定义的类型,如自定义结构,make 用于内置引用类型(切片、map 和管道)。它们的用法就像是函数,但是将类型作为参数:new(type)、make(type)。new(T) 分配类型 T 的零值并返回其地址,也就是指向类型 T 的指针。它也可以被用于基本类型:v := new(int)。make(T) 返回类型 T 的初始化之后的值,因此它比 new 进行更多的工作,new() 是一个函数,不要忘记它的括号 |
| copy、append | 用于复制和连接切片 |
| panic、recover | 两者均用于错误处理机制 |
| print、println | 底层打印函数,在部署环境中建议使用 fmt 包 |
| complex、real imag | 用于创建和操作复数 |
递归函数
经常遇到的问题是栈溢出:大量递归调用导致程序栈内存分配耗尽。可通过一个名为懒惰求值的技术解决,Go 中可以使用管道(channel)和 goroutine来实现。
函数作为参数
eg. 函数 strings.IndexFunc()
其函数签名是 func IndexFunc(s string, f func(c int) bool) int,它的返回值是在函数 f(c) 返回 true、-1 或从未返回时的索引值。
闭包
不想给函数起名字时,可以用匿名函数,例如: func(x, y int) int { return x + y }。
匿名函数不能独立存在,要赋值给变量(即保存函数的地址到变量中):fplus := func(x, y int) int { return x + y },然后用变量名来调用:fplus(3,4),或直接对匿名函数进行调用:func(x, y int) int { return x + y }(3, 4)。
defer语句和匿名函数
两者经常搭配,可用于改变函数的命名返回值。
匿名函数还可以配合 go 关键字来作为 goroutine 使用。
匿名函数被称之为闭包:被允许调用定义在起环境下的变量。闭包可使得某个函数捕捉到一些外部状态,如:函数被创建时的状态。或者说:一个闭包继承了函数所声明时的作用域。这种状态(作用域内的变量)都被共享到闭包的环境中,因此这些变量可以在闭包中被操作,直到被销毁。
闭包经常被用作包装函数:会预先定义好 1 个或多个参数以用于包装。
另一个应用是用闭包来完成更加简洁的错误检查。
应用闭包:将函数作为返回值
- 闭包函数保存并积累其中的变量的值,不管外部函数退出与否,它都能够继续操作外部函数中的局部变量。
- 闭包中使用到的变量可以是在闭包函数体内声明的,也可以是在外部函数声明的。
使用闭包调试
调试时需要准确知道哪个文件中的具体哪个函数正在执行。可以使用 runtime 或 log 包中的特殊函数来实现这样的功能。包 runtime 中的函数 Caller() 提供了相应的信息,因此可以在需要的时候实现一个 where() 闭包函数来打印函数执行的位置:
1 | where := func() { |
也可以设置 log 包中的 flag 参数来实现:
1 | log.SetFlags(log.Llongfile) |
或使用一个更加简短版本的 where 函数:
1 | var where = log.Print |
计算函数执行时间
在计算开始签设置一个起始时候,在计算结束时的结束时间,求差值。
可用 time 包中的 Now() 和 Sub 函数:
1 | start := time.Now() |
通过内存缓存来提升性能
大量计算式,提升性能最有效的一种方式是避免重复计算。通过在内存中缓存和重复利用相同计算的结果,成为内存缓存。
eg. 求斐波那契数列:
1 | package main |
包(package)
标准库
内置在 Go 语言中的,150 个以上。
unsafe: 包含了一些打破 Go 语言“类型安全”的命令,一般的程序中不会被使用,可用在 C/C++ 程序的调用中。syscall-os-os/exec:os: 提供给我们一个平台无关性的操作系统功能接口,采用类Unix设计,隐藏了不同操作系统间差异,让不同的文件系统和操作系统对象表现一致。os/exec: 提供我们运行外部操作系统命令和程序的方式。syscall: 底层的外部包,提供了操作系统底层调用的基本接口。
archive/tar和/zip-compress:压缩(解压缩)文件功能。fmt-io-bufio-path/filepath-flag:fmt: 提供了格式化输入输出功能。io: 提供了基本输入输出功能,大多数是围绕系统功能的封装。bufio: 缓冲输入输出功能的封装。path/filepath: 用来操作在当前系统中的目标文件名路径。flag: 对命令行参数的操作。
strings-strconv-unicode-regexp-bytes:strings: 提供对字符串的操作。strconv: 提供将字符串转换为基础类型的功能。unicode: 为 unicode 型的字符串提供特殊的功能。regexp: 正则表达式功能。bytes: 提供对字符型分片的操作。index/suffixarray: 子字符串快速查询。
math-math/cmath-math/big-math/rand-sort:math: 基本的数学函数。math/cmath: 对复数的操作。math/rand: 伪随机数生成。sort: 为数组排序和自定义集合。math/big: 大数的实现和计算。
container-/list-ring-heap: 实现对集合的操作。list: 双链表。ring: 环形链表。
time-log:time: 日期和时间的基本操作。log: 记录程序运行时产生的日志,我们将在后面的章节使用它。
encoding/json-encoding/xml-text/template:encoding/json: 读取并解码和写入并编码 JSON 数据。encoding/xml:简单的 XML1.0 解析器。text/template:生成像 HTML 一样的数据与文本混合的数据驱动模板。
net-net/http-htmlnet: 网络数据的基本操作。http: 提供了一个可扩展的 HTTP 服务器和基础客户端,解析 HTTP 请求和回复。html: HTML5 解析器。
runtime: Go 程序运行时的交互操作,例如垃圾回收和协程创建。reflect: 实现通过程序运行时反射,让程序操作任意类型的变量。
exp 包中有许多将被编译为新包的实验性的包。它们将成为独立的包在下次稳定版本发布的时候。如果前一个版本已经存在了,它们将被作为过时的包被回收。然而 Go1.0 发布的时候并不包含过时或者实验性的包。
regexp 包
正则表达式语法和使用见 维基百科
简单模式,用 Match 方法即可:
1 | ok, _ := regexp.Match(pat, []byte(searchIn)) // ok 将返回 true 或 false |
也可以用 MatchString:
1 | ok, _ := regexp.MatchString(pat, searchIn) |
更多方法中,必须先将正则通过 Compile 方法返回一个 Regexp 对象。Compile 函数也可能返回一个错误,我们在使用时忽略对错误的判断是因为我们确信自己正则表达式是有效的。当用户输入或从数据中获取正则表达式的时候,我们有必要去检验它的正确性。另外我们也可以使用 MustCompile 方法,它可以像 Compile 方法一样检验正则的有效性,但是当正则不合法时程序将 panic。
锁和 sync 包
多个线程同时操作一个变量时,可能会出错,需要锁。 这种锁的机制是通过 sync 包中 Mutex 来实现的。sync 来源于 “synchronized” 一词,这意味着线程将有序的对同一变量进行访问。sync.Mutex 是一个互斥锁,它的作用是守护在临界区入口来确保同一时间只能有一个线程进入临界区。
1 | import "sync" |
eg. 实现一个可以上锁的共享缓冲器:
1 | type SyncedBuffer struct { |
在 sync 包中还有一个 RWMutex 锁:他能通过 RLock() 来允许同一时间多个线程对变量进行读操作,但是只能一个线程进行写操作。如果使用 Lock() 将和普通的 Mutex 作用相同。包中还有一个方便的 Once 类型变量的方法 once.Do(call),这个方法确保被调用函数只能被调用一次。
相对简单的情况下,通过使用 sync 包可以解决同一时间只能一个线程访问变量或 map 类型数据的问题。如果这种方式导致程序明显变慢或者引起其他问题,我们要重新思考来通过 goroutines 和 channels 来解决问题,这是在 Go 语言中所提倡用来实现并发的技术。我们将在第 14 章对其深入了解,并在第 14.7 节中对这两种方式进行比较。
精密计算和 big 包
对于整数的高精度计算 Go 语言中提供了 big 包。其中包含了 math 包:有用来表示大整数的 big.Int 和表示大有理数的 big.Rat 类型(可以表示为 2/5 或 3.1416 这样的分数,而不是无理数或 π)。这些类型可以实现任意位类型的数字,只要内存足够大。缺点是更大的内存和处理开销使它们使用起来要比内置的数字类型慢很多。
大的整型数字是通过 big.NewInt(n) 来构造的,其中 n 为 int64 类型整数。而大有理数是用过 big.NewRat(N,D) 方法构造。N(分子)和 D(分母)都是 int64 型整数。因为 Go 语言不支持运算符重载,所以所有大数字类型都有像是 Add() 和 Mul() 这样的方法。它们作用于作为 receiver 的整数和有理数,大多数情况下它们修改 receiver 并以 receiver 作为返回结果。因为没有必要创建 big.Int 类型的临时变量来存放中间结果,所以这样的运算可通过内存链式存储。
自定义包和可见性
当写自己包的时候,要使用短小的不含有 _(下划线)的小写单词来为文件命名。
import 的一般格式如下:
1 | import "包的路径或 URL 地址" // 路径指当前目录的相对路径 |
Import with _ :pack1包只导入其副作用,也就是说,只执行它的init函数并初始化其中的全局变量。
1 | import _ "./pack1/pack1" |
导入外部安装包:
1 | go install codesite.ext/author/goExample/goex // ←网址 |
将一个名为 codesite.ext/author/goExample/goex 的 map 安装在 $GOROOT/src/ 目录下。
在 http://golang.org/cmd/goinstall/ 的 go install 文档中列出了一些广泛被使用的托管在网络代码仓库的包的导入路径
包的初始化:
程序的执行开始于导入包,初始化 main 包然后调用 main 函数。
一个没有导入的包将通过分配初始值给所有的包级变量和调用源码中定义的包级 init 函数来初始化。一个包可能有多个 init 函数甚至在一个源码文件中。它们的执行是无序的。这是最好的例子来测定包的值是否只依赖于相同包下的其他值或者函数。
init 函数是不能被调用的。
导入的包在包自身初始化前被初始化,而一个包在程序执行中只能初始化一次。
为自定义包使用 godoc
使用 go install 安装自定义包
自定义包的目录结构、go install 和 go test
通过 Git 打包和安装
Go 的外部包和项目
着手自己 Go 项目前,最好查下是否有存在的第三方包或项目可使用。大多可通过 go install 安装。
Go Walker 支持查询。
目前已经有许多非常好的外部库,如:
- MySQL(GoMySQL), PostgreSQL(go-pgsql), MongoDB (mgo, gomongo), CouchDB (couch-go), ODBC (godbcl), Redis (redis.go) and SQLite3 (gosqlite) database drivers
- SDL bindings
- Google’s Protocal Buffers(goprotobuf)
- XML-RPC(go-xmlrpc)
- Twitter(twitterstream)
- OAuth libraries(GoAuth)
在 Go 程序中使用外部库
读写数据
读取用户的输入
读取用户的键盘(控制台)输入,从键盘和标准输入 os.Stdin 读取输入,最简单的办法是用 fmt 包提供的 Scan 和 Sscan 开头的函数:
1 | package main |
Scanln 扫描来自标准输入的文本,将空格分隔的值依次存放到后续的参数内,直到碰到换行。Scanf 与其类似,除了 Scanf 的第一个参数用作格式字符串,用来决定如何读取。Sscan 和以 Sscan 开头的函数则是从字符串读取,除此之外,与 Scanf 相同。如果这些函数读取到的结果与您预想的不同,您可以检查成功读入数据的个数和返回的错误。
也可以用 bufio 包提供的缓冲读取(buffered reader)来读取数据:
1 | package main |
inputReader 是一个指向 bufio.Reader 的指针。inputReader := bufio.NewReader(os.Stdin) 这行代码,将会创建一个读取器,并将其与标准输入绑定。
bufio.NewReader() 构造函数的签名为:func NewReader(rd io.Reader) *Reader
该函数的实参可以是满足 io.Reader 接口的任意对象(任意包含有适当的 Read() 方法的对象,请参考章节11.8),函数返回一个新的带缓冲的 io.Reader 对象,它将从指定读取器(例如 os.Stdin)读取内容。
返回的读取器对象提供一个方法 ReadString(delim byte),该方法从输入中读取内容,直到碰到 delim 指定的字符,然后将读取到的内容连同 delim 字符一起放到缓冲区。
ReadString 返回读取到的字符串,如果碰到错误则返回 nil。如果它一直读到文件结束,则返回读取到的字符串和 io.EOF。如果读取过程中没有碰到 delim 字符,将返回错误 err != nil。
在上面的例子中,我们会读取键盘输入,直到回车键(\n)被按下。
屏幕是标准输出 os.Stdout;os.Stderr 用于显示错误信息,大多数情况下等同于 os.Stdout。
一般情况下,我们会省略变量声明,而使用 :=,例如:
1 | inputReader := bufio.NewReader(os.Stdin) |
第二个例子从键盘读取输入,使用了 switch 语句:
1 | package main |
文件读写
读文件
在 Go 语言中,文件使用指向 os.File 类型的指针来表示的,也叫做文件句柄。我们在前面章节使用到过标准输入 os.Stdin 和标准输出 os.Stdout,他们的类型都是 *os.File:
1 | package main |
变量 inputFile 是 *os.File 类型的。该类型是一个结构,表示一个打开文件的描述符(文件句柄)。然后,使用 os 包里的 Open 函数来打开一个文件。该函数的参数是文件名,类型为 string。在上面的程序中,我们以只读模式打开 input.dat 文件。
如果文件不存在或者程序没有足够的权限打开这个文件,Open函数会返回一个错误:inputFile, inputError = os.Open("input.dat")。如果文件打开正常,我们就使用 defer inputFile.Close() 语句确保在程序退出前关闭该文件。然后,我们使用 bufio.NewReader 来获得一个读取器变量。
通过使用 bufio 包提供的读取器(写入器也类似),如上面程序所示,我们可以很方便的操作相对高层的 string 对象,而避免了去操作比较底层的字节。
接着,我们在一个无限循环中使用 ReadString('\n') 或 ReadBytes('\n') 将文件的内容逐行(行结束符 ‘\n’)读取出来。
注意: 在之前的例子中,我们看到,Unix和Linux的行结束符是 \n,而Windows的行结束符是 \r\n。在使用 ReadString 和 ReadBytes 方法的时候,我们不需要关心操作系统的类型,直接使用 \n 就可以了。另外,我们也可以使用 ReadLine() 方法来实现相同的功能。
一旦读取到文件末尾,变量 readerError 的值将变成非空(事实上,常量 io.EOF 的值是 true),我们就会执行 return 语句从而退出循环。
其他类似函数:
1) 将整个文件的内容读到一个字符串里:
如果您想这么做,可以使用 io/ioutil 包里的 ioutil.ReadFile() 方法,该方法第一个返回值的类型是 []byte,里面存放读取到的内容,第二个返回值是错误,如果没有错误发生,第二个返回值为 nil。请看示例 12.5。类似的,函数 WriteFile() 可以将 []byte 的值写入文件。
1 | package main |
2) 带缓冲的读取
在很多情况下,文件的内容是不按行划分的,或者干脆就是一个二进制文件。在这种情况下,ReadString()就无法使用了,我们可以使用 bufio.Reader 的 Read(),它只接收一个参数:
1 | buf := make([]byte, 1024) |
变量 n 的值表示读取到的字节数.
3) 按列读取文件中的数据
如果数据是按列排列并用空格分隔的,你可以使用 fmt 包提供的以 FScan 开头的一系列函数来读取他们。请看以下程序,我们将 3 列的数据分别读入变量 v1、v2 和 v3 内,然后分别把他们添加到切片的尾部。
1 | package main |
输出结果:
1 | [ABC FUNC GO] |
注意: path 包里包含一个子包叫 filepath,这个子包提供了跨平台的函数,用于处理文件名和路径。例如 Base() 函数用于获得路径中的最后一个元素(不包含后面的分隔符):
1 | import "path/filepath" |
compress 包:读取压缩文件
compress包提供了读取压缩文件的功能,支持的压缩文件格式为:bzip2、flate、gzip、lzw 和 zlib。
下面的程序展示了如何读取一个 gzip 文件。
1 | package main |
写文件
1 | package main |
除了文件句柄,我们还需要 bufio 的 Writer。我们以只写模式打开文件 output.dat,如果文件不存在则自动创建:
1 | outputFile, outputError := os.OpenFile("output.dat", os.O_WRONLY|os.O_CREATE, 0666) |
可以看到,OpenFile 函数有三个参数:文件名、一个或多个标志(使用逻辑运算符“|”连接),使用的文件权限。
我们通常会用到以下标志:
os.O_RDONLY:只读os.O_WRONLY:只写os.O_CREATE:创建:如果指定文件不存在,就创建该文件。os.O_TRUNC:截断:如果指定文件已存在,就将该文件的长度截为0。
在读文件的时候,文件的权限是被忽略的,所以在使用 OpenFile 时传入的第三个参数可以用0。而在写文件时,不管是 Unix 还是 Windows,都需要使用 0666。
然后,我们创建一个写入器(缓冲区)对象:
1 | outputWriter := bufio.NewWriter(outputFile) |
接着,使用一个 for 循环,将字符串写入缓冲区,写 10 次:outputWriter.WriteString(outputString)
缓冲区的内容紧接着被完全写入文件:outputWriter.Flush()
如果写入的东西很简单,我们可以使用 fmt.Fprintf(outputFile, "Some test data.\n") 直接将内容写入文件。fmt 包里的 F 开头的 Print 函数可以直接写入任何 io.Writer,包括文件。
程序 filewrite.go 展示了不使用 fmt.FPrintf 函数,使用其他函数如何写文件:
1 | package main |
使用 os.Stdout.WriteString("hello, world\n"),我们可以输出到屏幕。
我们以只写模式创建或打开文件”test”,并且忽略了可能发生的错误:f, _ := os.OpenFile("test", os.O_CREATE|os.O_WRONLY, 0666)
我们不使用缓冲区,直接将内容写入文件:f.WriteString( )
文件拷贝
用 io 包:
1 | // filecopy.go |
注意 defer 的使用:当打开目标文件时发生了错误,那么 defer 仍然能够确保 src.Close() 执行。如果不这么做,文件会一直保持打开状态并占用资源。
从命令行读参数
os 包
os 包中有一个 string 类型的切片变量 os.Args,用来处理一些基本的命令行参数,它在程序启动后读取命令行输入的参数。来看下面的打招呼程序:
1 | // os_args.go |
我们在 IDE 或编辑器中直接运行这个程序输出:Good Morning Alice
我们在命令行运行 os_args or ./os_args 会得到同样的结果。
但是我们在命令行加入参数,像这样:os_args John Bill Marc Luke,将得到这样的输出:Good Morning Alice John Bill Marc Luke
这个命令行参数会放置在切片 os.Args[] 中(以空格分隔),从索引1开始(os.Args[0] 放的是程序本身的名字,在本例中是 os_args)。函数 strings.Join 以空格为间隔连接这些参数。
flag 包
flag 包有一个扩展功能用来解析命令行选项。但是通常被用来替换基本常量,例如,在某些情况下我们希望在命令行给常量一些不一样的值。
在 flag 包中有一个 Flag 被定义成一个含有如下字段的结构体:
1 | type Flag struct { |
模拟 Unix 的 echo 功能:
1 | package main |
flag.Parse() 扫描参数列表(或者常量列表)并设置 flag, flag.Arg(i) 表示第i个参数。Parse() 之后 flag.Arg(i) 全部可用,flag.Arg(0) 就是第一个真实的 flag,而不是像 os.Args(0) 放置程序的名字。
flag.Narg() 返回参数的数量。解析后 flag 或常量就可用了。flag.Bool() 定义了一个默认值是 false 的 flag:当在命令行出现了第一个参数(这里是 “n”),flag 被设置成 true(NewLine 是 *bool 类型)。flag 被解引用到 *NewLine,所以当值是 true 时将添加一个 Newline(”\n”)。
flag.PrintDefaults() 打印 flag 的使用帮助信息,本例中打印的是:
1 | -n=false: print newline |
flag.VisitAll(fn func(*Flag)) 是另一个有用的功能:按照字典顺序遍历 flag,并且对每个标签调用 fn
当在命令行(Windows)中执行:echo.exe A B C,将输出:A B C;执行 echo.exe -n A B C,将输出:
1 | A |
每个字符的输出都新起一行,每次都在输出的数据前面打印使用帮助信息:-n=false: print newline。
对于 flag.Bool 你可以设置布尔型 flag 来测试你的代码,例如定义一个 flag processedFlag:
1 | var processedFlag = flag.Bool("proc", false, "nothing processed yet") |
在后面用如下代码来测试:
1 | if *processedFlag { // found flag -proc |
要给 flag 定义其它类型,可以使用 flag.Int(),flag.Float64(),flag.String()。
用 buffer 读取文件
使用了缓冲读取文件和命令行 flag 解析这两项技术。如果不加参数,那么你输入什么屏幕就打印什么。
参数被认为是文件名,如果文件存在的话就打印文件内容到屏幕。命令行执行 cat test 测试输出。
1 | package main |
用切片读写文件
切片提供了 Go 中处理 I/O 缓冲的标准方式,下面 cat 函数的第二版中,在一个切片缓冲内使用无限 for 循环(直到文件尾部 EOF)读取文件,并写入到标准输出(os.Stdout)。
1 | func cat(f *os.File) { |
上面的代码来自于 cat2.go,使用了 os 包中的 os.File 和 Read 方法;cat2.go 与 cat.go 具有同样的功能。
1 | package main |
用 defer 关闭文件
1 | func data(name string) string { |
在函数 return 后执行了 f.Close()
使用接口的实际例子:fmt.Fprintf
例子程序 io_interfaces.go 很好的阐述了 io 包中的接口概念:
1 | // interfaces being used in the GO-package fmt |
输出:
1 | hello world! - unbuffered |
fmt.Fprintf() 函数的实际签名:
1 | func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error) |
其不是写入一个文件,而是写入一个 io.Writer 接口类型的变量,下面是 Writer 接口在 io 包中的定义:
1 | type Writer interface { |
fmt.Fprintf() 依据指定的格式向第一个参数内写入字符串,第一个参数必须实现了 io.Writer 接口。Fprintf() 能够写入任何类型,只要其实现了 Write 方法,包括 os.Stdout,文件(例如 os.File),管道,网络连接,通道等等,同样的也可以使用 bufio 包中缓冲写入。bufio 包中定义了 type Writer struct{...}。
bufio.Writer 实现了 Write 方法:
1 | func (b *Writer) Write(p []byte) (nn int, err error) |
它还有一个工厂函数:传给它一个 io.Writer 类型的参数,它会返回一个带缓冲的 bufio.Writer 类型的 io.Writer:
1 | func NewWriter(wr io.Writer) (b *Writer) |
其适合任何形式的缓冲写入。
在缓冲写入的最后千万不要忘了使用 Flush(),否则最后的输出不会被写入。
JSON 数据格式
数据结构要在网络中传输或保存到文件,就必须对其编码和解码;目前存在很多编码格式:JSON,XML,gob,Google 缓冲协议等等。Go 语言支持所有这些编码格式。
术语说明:
- 数据结构 –> 指定格式 =
序列化或编码(传输之前) - 指定格式 –> 数据格式 =
反序列化或解码(传输之后)
序列化是在内存中把数据转换成指定格式(data -> string),反之亦然(string -> data structure)
编码也是一样的,只是输出一个数据流(实现了 io.Writer 接口);解码是从一个数据流(实现了 io.Reader)输出到一个数据结构。
JSON 有时候是首选,由于其格式上非常简洁。通常 JSON 被用于 web 后端和浏览器之间的通讯,但是在其它场景也同样的有用。
一个简短的 JSON 片段:
1 | { |
1 | // json.go |
json.Marshal() 的函数签名是 func Marshal(v interface{}) ([]byte, error),下面是数据编码后的 JSON 文本(实际上是一个 []byte):
1 | { |
出于安全考虑,在 web 应用中最好使用 json.MarshalforHTML() 函数,其对数据执行HTML转码,所以文本可以被安全地嵌在 HTML <script> 标签中。
json.NewEncoder() 的函数签名是 func NewEncoder(w io.Writer) *Encoder,返回的Encoder类型的指针可调用方法 Encode(v interface{}),将数据对象 v 的json编码写入 io.Writer w 中。
JSON 与 Go 类型对应如下:
- bool 对应 JSON 的 booleans
- float64 对应 JSON 的 numbers
- string 对应 JSON 的 strings
- nil 对应 JSON 的 null
不是所有的数据都可以编码为 JSON 类型:只有验证通过的数据结构才能被编码:
JSON 对象只支持字符串类型的 key;要编码一个 Go map 类型,map 必须是 map[string]T(T是
json包中支持的任何类型)Channel,复杂类型和函数类型不能被编码
不支持循环数据结构;它将引起序列化进入一个无限循环
指针可以被编码,实际上是对指针指向的值进行编码(或者指针是 nil)
XML 数据格式
用 Gob 传输数据
Gob 是 Go 自己的以二进制形式序列化和反序列化程序数据的格式;可以在 encoding 包中找到。这种格式的数据简称为 Gob (即 Go binary 的缩写)。类似于 Python 的 “pickle” 和 Java 的 “Serialization”。
The way to Go 参考内容
Go 中的密码学
Go 为加密提供了超过 30 个包:
hash包:实现了adler32、crc32、crc64和fnv校验;crypto包:实现了其它的 hash 算法,比如md4、md5、sha1等。以及完整地实现了aes、blowfish、rc4、rsa、xtea等加密算法。
1 | // hash_sha1.go |
输出:
1 | Result: a94a8fe5ccb19ba61c4c0873d391e987982fbbd3 |
通过调用 sha1.New() 创建了一个新的 hash.Hash 对象,用来计算 SHA1 校验值。Hash 类型实际上是一个接口,它实现了 io.Writer 接口:
1 | type Hash interface { |
通过 io.WriteString 或 hasher.Write 将给定的 []byte 附加到当前的 hash.Hash 对象中。
错误处理与测试
永远不要忽略错误,否则可能会导致程序崩溃!!
panic and recover 是用来处理真正的异常(无法预测的错误)而不是普通的错误。
1 | if value, err := pack1.Func1(param1); err != nil { |
除了 fmt.Printf 还可以使用 log 中对应的方法,如果程序中止也没关系的话甚至可以使用 panic
错误处理
Go 有一个预先定义的 error 接口类型
1 | type error interface { |
当程序处于错误状态时可以用 os.Exit(1) 来中止运行。
定义错误
用 errors(必须先 import)包的 errors.New 函数接收合适的错误信息来创建:
1 | err := errors.New("math - square root of negative number") |
1 | package main |
用于计算平方根函数的参数测试:
1 | func Sqrt(f float64) (float64, error) { |
1 | if f, err := Sqrt(-1); err != nil { |
由于 fmt.Printf 会自动调用 String() 方法 (参见 10.7 节),所以错误信息 “Error: math - square root of negative number” 会打印出来。通常(错误信息)都会有像 “Error:” 这样的前缀,所以你的错误信息不要以大写字母开头。
有不同错误条件可能发生,那么对实际的错误使用类型断言或类型判断(type-switch)是很有用的,并且可以根据错误场景做一些补救和恢复操作。
1 | // PathError records an error and the operation and file path that caused it. |
或:
1 | switch err := err.(type) { |
例子:当 json.Decode 在解析 JSON 文档发生语法错误时,指定返回一个 SyntaxError 类型的错误:
1 | type SyntaxError struct { |
在调用代码中你可以像这样用类型断言测试错误是不是上面的类型:
1 | if serr, ok := err.(*json.SyntaxError); ok { |
包也可以用额外的方法(methods)定义特定的错误,比如 net.Error:
1 | package net |
遵循同一种命名规范:错误类型以 “Error” 结尾,错误变量以 “err” 或 “Err” 开头。
用 fmt 创建错误对象
可以用 fmt.Errorf() 来实现:它和 fmt.Printf() 完全一样,接收一个或多个格式占位符的格式化字符串和相应数量的占位变量。和打印信息不同的是它用信息生成错误对象。
1 | if f < 0 { |
例子2:从命令行读取输入时,如果加了 help 标志,我们可以用有用的信息产生一个错误:
1 | if len(os.Args) > 1 && (os.Args[1] == "-h" || os.Args[1] == "--help") { |
运行时异常和 panic
当发生像数组下标越界或类型断言失败这样的运行错误时,Go 运行时会触发运行时 panic,伴随着程序的崩溃抛出一个 runtime.Error 接口类型的值。这个错误值有个 RuntimeError() 方法用于区别普通错误。
panic 可以直接从代码初始化:当错误条件(我们所测试的代码)很严苛且不可恢复,程序不能继续运行时,可以使用 panic 函数产生一个中止程序的运行时错误。panic 接收一个做任意类型的参数,通常是字符串,在程序死亡时被打印出来。Go 运行时负责中止程序并给出调试信息:
1 | package main |
输出:
1 | Starting the program |
一个检查程序是否被已知用户启动的具体例子:
1 | var user = os.Getenv("USER") |
可以在导入包的 init() 函数中检查这些。
当发生错误必须中止程序时,panic 可以用于错误处理模式:
1 | if err != nil { |
Go panicking:
在多层嵌套的函数调用中调用 panic,可以马上中止当前函数的执行,所有的 defer 语句都会保证执行并把控制权交还给接收到 panic 的函数调用者。这样向上冒泡直到最顶层,并执行(每层的) defer,在栈顶处程序崩溃,并在命令行中用传给 panic 的值报告错误情况:这个终止过程就是 panicking。
标准库中有许多包含 Must 前缀的函数,像 regexp.MustComplie 和 template.Must;当正则表达式或模板中转入的转换字符串导致错误时,这些函数会 panic。
不能随意地用 panic 中止程序,必须尽力补救错误让程序能继续执行。
从 panic 中恢复(Recover)
这个(recover)内建函数被用于从 panic 或 错误场景中恢复:让程序可以从 panicking 重新获得控制权,停止终止过程进而恢复正常执行。
recover 只能在 defer 修饰的函数中使用:用于取得 panic 调用中传递过来的错误值,如果是正常执行,调用 recover 会返回 nil,且没有其它效果。
总结:panic 会导致栈被展开直到 defer 修饰的 recover() 被调用或者程序中止。
1 | func protect(g func()) { |
log 包实现了简单的日志功能:默认的 log 对象向标准错误输出中写入并打印每条日志信息的日期和时间。除了 Println 和 Printf 函数,其它的致命性函数都会在写完日志信息后调用 os.Exit(1),那些退出函数也是如此。而 Panic 效果的函数会在写完日志信息后调用 panic;可以在程序必须中止或发生了临界错误时使用它们,就像当 web 服务器不能启动时那样。
一个展示 panic,defer 和 recover 怎么结合使用的完整例子:
1 | // panic_recover.go |
输出:
1 | Calling test |
自定义包中的错误处理和 panicking
这是所有自定义包实现者应该遵守的最佳实践:
1)在包内部,总是应该从 panic 中 recover:不允许显式的超出包范围的 panic()
2)向包的调用者返回错误值(而不是 panic)。
一种用闭包处理错误的模式
模式中使用了两个帮助函数:
1)check:这是用来检查是否有错误和 panic 发生的函数:
1 | func check(err error) { if err != nil { panic(err) } } |
2)errorhandler:这是一个包装函数。接收一个 fType1 类型的函数 fn 并返回一个调用 fn 的函数。里面就包含有 defer/recover 机制,这在 13.3 节中有相应描述。
1 | func errorHandler(fn fType1) fType1 { |
启动外部命令和程序
os 包有一个 StartProcess 函数可以调用或启动外部系统命令和二进制可执行文件;它的第一个参数是要运行的进程,第二个参数用来传递选项或参数,第三个参数是含有系统环境基本信息的结构体。
这个函数返回被启动进程的 id(pid),或者启动失败返回错误。
exec 包中也有同样功能的更简单的结构体和函数;主要是 exec.Command(name string, arg ...string) 和 Run()。首先需要用系统命令或可执行文件的名字创建一个 Command 对象,然后用这个对象作为接收者调用 Run()。
Go 中的单元测试和基准测试
测试的具体例子:
The way to Go 参考内容
用(测试数据)表驱动测试:
The way to Go 参考内容
性能调试:分析并优化 Go 程序
时间和内存消耗、用 go test 调试、用 pprof 调试: The way to Go 参考内容
协程(goroutine)与通道(channel)
不要通过共享内存来通信,而通过通信来共享内存。
并发、并行和协程
在 Go 中,应用程序并发处理的部分被称作 goroutines(协程)。
Go 使用 channels 来同步协程。
协程是通过使用关键字 go 调用(执行)一个函数或者方法来实现的(也可以是匿名或者 lambda 函数)。这样会在当前的计算过程中开始一个同时进行的函数,在相同的地址空间中并且分配了独立的栈,比如:go sum(bigArray),在后台计算总和。
协程的栈会根据需要进行伸缩,不出现栈溢出;开发者不需要关心栈的大小。当协程结束的时候,它会静默退出:用来启动这个协程的函数不会得到任何的返回值。
在一个协程中,比如它需要进行非常密集的运算,你可以在运算循环中周期的使用 runtime.Gosched():这会让出处理器,允许运行其他协程;它并不会使当前协程挂起,所以它会自动恢复执行。使用 Gosched() 可以使计算均匀分布,使通信不至于迟迟得不到响应。
并发和并行的差异
Go 的并发原语提供了良好的并发设计基础:表达程序结构以便表示独立地执行的动作。
在当前的运行时(2012 年一月)实现中,Go 默认没有并行指令,只有一个独立的核心或处理器被专门用于 Go 程序,不论它启动了多少个协程;所以这些协程是并发运行的,但他们不是并行运行的:同一时间只有一个协程会处在运行状态。
使用 GOMAXPROCS
在 gc 编译器下(6g 或者 8g)你必须设置 GOMAXPROCS 为一个大于默认值 1 的数值来允许运行时支持使用多于 1 个的操作系统线程,所有的协程都会共享同一个线程除非将 GOMAXPROCS 设置为一个大于 1 的数。当 GOMAXPROCS 大于 1 时,会有一个线程池管理许多的线程。通过 gccgo 编译器 GOMAXPROCS 有效的与运行中的协程数量相等。假设 n 是机器上处理器或者核心的数量。如果你设置环境变量 GOMAXPROCS>=n,或者执行 runtime.GOMAXPROCS(n),接下来协程会被分割(分散)到 n 个处理器上。更多的处理器并不意味着性能的线性提升。有这样一个经验法则,对于 n 个核心的情况设置 GOMAXPROCS 为 n-1 以获得最佳性能,也同样需要遵守这条规则:协程的数量 > 1 + GOMAXPROCS > 1。
所以如果在某一时间只有一个协程在执行,不要设置 GOMAXPROCS!
总结:GOMAXPROCS 等同于(并发的)线程数量,在一台核心数多于1个的机器上,会尽可能有等同于核心数的线程在并行运行。
如何用命令行指定使用的核心数量
使用 flags 包,如下:
1 | var numCores = flag.Int("n", 2, "number of CPU cores to use") |
协程可以通过调用runtime.Goexit()来停止,尽管这样做几乎没有必要。
1 | package main |
输出:
1 | In main() |
当 main() 函数返回的时候,程序退出:它不会等待任何其他非 main 协程的结束。这就是为什么在服务器程序中,每一个请求都会启动一个协程来处理,server() 函数必须保持运行状态。通常使用一个无限循环来达到这样的目的。
Go 协程(goroutines)和协程(coroutines)
在其他语言中,比如 C#,Lua 或者 Python 都有协程的概念。这个名字表明它和 Go协程有些相似,但有两点不同:
- Go 协程意味着并行(或者可以以并行的方式部署),协程一般来说不是这样的
- Go 协程通过通道来通信;协程通过让出和恢复操作来通信
Go 协程比协程更强大,也很容易从协程的逻辑复用到 Go 协程。
协程间的信道
概念
Go 有一种特殊的类型,通道(channel),就像一个可以用于发送类型化数据的管道,由其负责协程之间的通信,从而避开所有由共享内存导致的陷阱;这种通过通道进行通信的方式保证了同步性。数据在通道中进行传递:在任何给定时间,一个数据被设计为只有一个协程可以对其访问,所以不会发生数据竞争。 数据的所有权(可以读写数据的能力)也因此被传递。
声明通道:var identifier chan datatype
未初始化的通道的值是nil。
所以通道只能传输一种类型的数据,比如 chan int 或者 chan string,所有的类型都可以用于通道,空接口 interface{} 也可以。甚至可以(有时非常有用)创建通道的通道。
通道实际上是类型化消息的队列:使数据得以传输。它是先进先出(FIFO)的结构所以可以保证发送给他们的元素的顺序(有些人知道,通道可以比作 Unix shells 中的双向管道(two-way pipe))。通道也是引用类型,所以我们使用 make() 函数来给它分配内存。这里先声明了一个字符串通道 ch1,然后创建了它(实例化):
1 | var ch1 chan string |
可以更短: ch1 := make(chan string)
构建一个int通道的通道: chanOfChans := make(chan int)
或者函数通道:funcChan := make(chan func())
所以通道是对象的第一类型:可以存储在变量中,作为函数的参数传递,从函数返回以及通过通道发送它们自身。另外它们是类型化的,允许类型检查,比如尝试使用整数通道发送一个指针。
通信操作符 <-
这个操作符直观的标示了数据的传输:信息按照箭头的方向流动。
流向通道(发送)
ch <- int1 表示:用通道 ch 发送变量 int1(双目运算符,中缀 = 发送)
从通道流出(接收),三种方式:
int2 = <- ch 表示:变量 int2 从通道 ch(一元运算的前缀操作符,前缀 = 接收)接收数据(获取新值);假设 int2 已经声明过了,如果没有的话可以写成:int2 := <- ch。
<- ch 可以单独调用获取通道的(下一个)值,当前值会被丢弃,但是可以用来验证,所以以下代码是合法的:
1 | if <- ch != 1000{ |
操作符 <- 也被用来发送和接收,Go 尽管不必要,为了可读性,通道的命名通常以 ch 开头或者包含 chan。通道的发送和接收操作都是自动的:它们通常一气呵成。例子:
1 | package main |
输出:
1 | Washington Tripoli London Beijing tokyo |
main() 函数中启动了两个协程:sendData() 通过通道 ch 发送了 5 个字符串,getData() 按顺序接收它们并打印出来。
如果 2 个协程需要通信,你必须给他们同一个通道作为参数才行。
协程之间的同步非常重要:
- main() 等待了 1 秒让两个协程完成,如果不这样,sendData() 就没有机会输出。
- getData() 使用了无限循环:它随着 sendData() 的发送完成和 ch 变空也结束了。
- 如果我们移除一个或所有
go关键字,程序无法运行,Go 运行时会抛出 panic:
1 | ---- Error run E:/Go/Goboek/code examples/chapter 14/goroutine2.exe with code Crashed ---- Program exited with code -2147483645: panic: all goroutines are asleep-deadlock! |
为什么会这样?运行时会检查所有的协程(也许只有一个是这种情况)是否在等待(可以读取或者写入某个通道),意味着程序无法处理。这是死锁(deadlock)形式,运行时可以检测到这种情况。
注意:不要使用打印状态来表明通道的发送和接收顺序:由于打印状态和通道实际发生读写的时间延迟会导致和真实发生的顺序不同。
通道阻塞
1)对于同一个通道,发送操作(协程或者函数中的),在接收者准备好之前是阻塞的:如果ch中的数据无人接收,就无法再给通道传入其他数据:新的输入无法在通道非空的情况下传入。所以发送操作会等待 ch 再次变为可用状态:就是通道值被接收时(可以传入变量)。
2)对于同一个通道,接收操作是阻塞的(协程或函数中的),直到发送者可用:如果通道中没有数据,接收者就阻塞了。
通过一个(或多个)通道交换数据进行协程同步
通信是一种同步形式:通过通道,两个协程在通信(协程会和)中某刻同步交换数据。无缓冲通道成为了多个协程同步的完美工具。
甚至可以在通道两端互相阻塞对方,形成了叫做死锁的状态。Go 运行时会检查并 panic,停止程序。死锁几乎完全是由糟糕的设计导致的。
无缓冲通道会被阻塞。设计无阻塞的程序可以避免这种情况,或者使用带缓冲的通道。
同步通道-使用带缓冲的通道
一个无缓冲通道只能包含 1 个元素,有时显得很局限。我们给通道提供了一个缓存,可以在扩展的 make 命令中设置它的容量,如下:
1 | buf := 100 |
buf 是通道可以同时容纳的元素(这里是 string)个数
在缓冲满载(缓冲被全部使用)之前,给一个带缓冲的通道发送数据是不会阻塞的,而从通道读取数据也不会阻塞,直到缓冲空了。
缓冲容量和类型无关,所以可以(尽管可能导致危险)给一些通道设置不同的容量,只要他们拥有同样的元素类型。内置的 cap 函数可以返回缓冲区的容量。
如果容量大于 0,通道就是异步的了:缓冲满载(发送)或变空(接收)之前通信不会阻塞,元素会按照发送的顺序被接收。如果容量是0或者未设置,通信仅在收发双方准备好的情况下才可以成功。
同步:ch :=make(chan type, value)
- value == 0 -> synchronous, unbuffered (阻塞)
- value > 0 -> asynchronous, buffered(非阻塞)取决于value元素
若使用通道的缓冲,你的程序会在“请求”激增的时候表现更好:更具弹性,专业术语叫:更具有伸缩性(scalable)。要在首要位置使用无缓冲通道来设计算法,只在不确定的情况下使用缓冲。
协程中用通道输出结果
为了知道计算何时完成,可以通过信道回报。在例子 go sum(bigArray) 中,要这样写:
1 | ch := make(chan int) |
也可以使用通道来达到同步的目的,这个很有效的用法在传统计算机中称为信号量(semaphore)。或者换个方式:通过通道发送信号告知处理已经完成(在协程中)。
在其他协程运行时让 main 程序无限阻塞的通常做法是在 main 函数的最后放置一个{}。
也可以使用通道让 main 程序等待协程完成,就是所谓的信号量模式:
信号量模式
协程通过在通道 ch 中放置一个值来处理结束的信号。main 协程等待 <-ch 直到从中获取到值。
我们期望从这个通道中获取返回的结果,像这样:
1 | func compute(ch chan int){ |
这个信号也可以是其他的,不返回结果,比如下面这个协程中的匿名函数(lambda)协程:
1 | ch := make(chan int) |
或者等待两个协程完成,每一个都会对切片s的一部分进行排序,片段如下:
1 | done := make(chan bool) |
下边的代码,用完整的信号量模式对长度为N的 float64 切片进行了 N 个doSomething() 计算并同时完成,通道 sem 分配了相同的长度(切包含空接口类型的元素),待所有的计算都完成后,发送信号(通过放入值)。在循环中从通道 sem 不停的接收数据来等待所有的协程完成。
1 | type Empty interface {} |
注意闭合:i、xi 都是作为参数传入闭合函数的,从外层循环中隐藏了变量 i 和 xi。让每个协程有一份 i 和 xi 的拷贝;另外,for 循环的下一次迭代会更新所有协程中 i 和 xi 的值。切片 res 没有传入闭合函数,因为协程不需要单独拷贝一份。切片 res 也在闭合函数中但并不是参数。
实现并行的 for 循环
在 for 循环中并行计算迭代可能带来很好的性能提升。不过所有的迭代都必须是独立完成的。for 循环的每一个迭代是并行完成的:
1 | for i, v := range data { |
用带缓冲通道实现一个信号量
信号量是实现互斥锁(排外锁)常见的同步机制,限制对资源的访问,解决读写问题,比如没有实现信号量的 sync 的 Go 包,使用带缓冲的通道可以轻松实现:
- 带缓冲通道的容量和要同步的资源容量相同
- 通道的长度(当前存放的元素个数)与当前资源被使用的数量相同
- 容量减去通道的长度就是未处理的资源个数(标准信号量的整数值)
不用管通道中存放的是什么,只关注长度;因此我们创建了一个长度可变但容量为0(字节)的通道:
1 | type Empty interface {} |
将可用资源的数量N来初始化信号量 semaphore:sem = make(semaphore, N)
然后直接对信号量进行操作:
1 | // acquire n resources |
可以用来实现一个互斥的例子:
1 | /* mutexes */ |
给通道使用 for 循环
for 循环的 range 语句可以用在通道 ch 上,便可以从通道中获取值,像这样:
1 | for v := range ch { |
习惯用法:通道迭代模式
这个模式用到了后边14.6章示例 producer_consumer.go 的生产者-消费者模式,通常,需要从包含了地址索引字段 items 的容器给通道填入元素。为容器的类型定义一个方法 Iter(),返回一个只读的通道(参见第 14.2.8 节)items,如下:
1 | func (c *container) Iter () <- chan item { |
在协程里,一个 for 循环迭代容器 c 中的元素(对于树或图的算法,这种简单的 for 循环可以替换为深度优先搜索)。
调用这个方法的代码可以这样迭代容器:
1 | for x := range container.Iter() { ... } |
可以运行在自己的协程中,所以上边的迭代用到了一个通道和两个协程(可能运行在两个线程上)。就有了一个特殊的生产者-消费者模式。如果程序在协程给通道写完值之前结束,协程不会被回收;设计如此。这种行为看起来是错误的,但是通道是一种线程安全的通信。在这种情况下,协程尝试写入一个通道,而这个通道永远不会被读取,这可能是个 bug 而并非期望它被静默的回收。
习惯用法:生产者消费者模式
假设你有 Produce() 函数来产生 Consume 函数需要的值。它们都可以运行在独立的协程中,生产者在通道中放入给消费者读取的值。整个处理过程可以替换为无限循环:
1 | for { |
通道的方向
通道类型可以用注解来表示它只发送或者只接收:
1 | var send_only chan<- int // channel can only receive data |
只接收的通道(<-chan T)无法关闭,因为关闭通道是发送者用来表示不再给通道发送值了,所以对只接收通道是没有意义的。通道创建的时候都是双向的,但也可以分配有方向的通道变量,就像以下代码:
1 | var c = make(chan int) // bidirectional |
习惯用法:管道和选择器模式
更具体的例子还有协程处理它从通道接收的数据并发送给输出通道:
1 | sendChan := make(chan int) |
通过使用方向注解来限制协程对通道的操作。
这里有一个来自 Go 指导的很赞的例子,打印了输出的素数,使用选择器(‘筛’)作为它的算法。每个 prime 都有一个选择器,如下图:
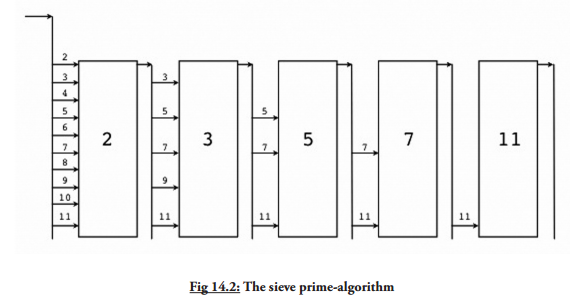
1 | // Copyright 2009 The Go Authors. All rights reserved. |
协程 filter(in, out chan int, prime int) 拷贝整数到输出通道,丢弃掉可以被 prime 整除的数字。然后每个 prime 又开启了一个新的协程,生成器和选择器并发请求。
输出:
1 | 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 101 |
第二个版本引入了上边的习惯用法:函数 sieve、generate 和 filter 都是工厂;它们创建通道并返回,而且使用了协程的 lambda 函数。main 函数现在短小清晰:它调用 sieve() 返回了包含素数的通道,然后通过 fmt.Println(<-primes) 打印出来。
版本2:示例 14.8-sieve2.go:
1 | // Copyright 2009 The Go Authors. All rights reserved. |
协程的同步:关闭通道-测试阻塞的通道
通道可以被显式的关闭;尽管它们和文件不同:不必每次都关闭。只有在当需要告诉接收者不会再提供新的值的时候,才需要关闭通道。只有发送者需要关闭通道,接收者永远不会需要。
继续看示例 goroutine2.go:我们如何在通道的 sendData() 完成的时候发送一个信号,getData() 又如何检测到通道是否关闭或阻塞?
第一个可以通过函数 close(ch) 来完成:这个将通道标记为无法通过发送操作 <- 接受更多的值;给已经关闭的通道发送或者再次关闭都会导致运行时的 panic。在创建一个通道后使用 defer 语句是个不错的办法(类似这种情况):
1 | ch := make(chan float64) |
第二个问题可以使用逗号,ok 操作符:用来检测通道是否被关闭。
如何来检测可以收到没有被阻塞(或者通道没有被关闭)?
1 | v, ok := <-ch // ok is true if v received value |
通常和 if 语句一起使用:
1 | if v, ok := <-ch; ok { |
或者在 for 循环中接收的时候,当关闭或者阻塞的时候使用 break:
1 | v, ok := <-ch |
在示例程序 14.2 中使用这些可以改进为版本 goroutine3.go,输出相同。
实现非阻塞通道的读取,需要使用 select。
示例 14.9-goroutine3.go:
1 | package main |
改变了以下代码:
- 现在只有
sendData()是协程,getData()和main()在同一个线程中:
1 | go sendData(ch) |
- 在
sendData()函数的最后,关闭了通道:
1 | func sendData(ch chan string) { |
- 在 for 循环的
getData()中,在每次接收通道的数据之前都使用if !open来检测:
1 | for { |
使用 for-range 语句来读取通道是更好的办法,因为这会自动检测通道是否关闭:
1 | for input := range ch { |
阻塞和生产者-消费者模式:
在第 14.2.10 节的通道迭代器中,两个协程经常是一个阻塞另外一个。如果程序工作在多核心的机器上,大部分时间只用到了一个处理器。可以通过使用带缓冲(缓冲空间大于 0)的通道来改善。比如,缓冲大小为 100,迭代器在阻塞之前,至少可以从容器获得 100 个元素。如果消费者协程在独立的内核运行,就有可能让协程不会出现阻塞。
由于容器中元素的数量通常是已知的,需要让通道有足够的容量放置所有的元素。这样,迭代器就不会阻塞(尽管消费者协程仍然可能阻塞)。然后,这样有效的加倍了迭代容器所需要的内存使用量,所以通道的容量需要限制一下最大值。记录运行时间和性能测试可以帮助你找到最小的缓存容量带来最好的性能。
使用 select 切换协程
从不同的并发执行的协程中获取值可以通过关键字select来完成,它和switch控制语句非常相似(章节5.3)也被称作通信开关;它的行为像是“你准备好了吗”的轮询机制;select监听进入通道的数据,也可以是用通道发送值的时候。
1 | select { |
default 语句是可选的;fallthrough 行为,和普通的 switch 相似,是不允许的。在任何一个 case 中执行 break 或者 return,select 就结束了。
select 做的就是:选择处理列出的多个通信情况中的一个。
- 如果都阻塞了,会等待直到其中一个可以处理
- 如果多个可以处理,随机选择一个
- 如果没有通道操作可以处理并且写了
default语句,它就会执行:default永远是可运行的(这就是准备好了,可以执行)。
在 select 中使用发送操作并且有 default 可以确保发送不被阻塞!如果没有 default,select 就会一直阻塞。
select 语句实现了一种监听模式,通常用在(无限)循环中;在某种情况下,通过 break 语句使循环退出。
在程序 goroutine_select.go中有 2 个通道 ch1 和 ch2,三个协程 pump1()、pump2() 和 suck()。这是一个典型的生产者消费者模式。在无限循环中,ch1 和 ch2 通过 pump1() 和 pump2() 填充整数;suck() 也是在无限循环中轮询输入的,通过 select 语句获取 ch1 和 ch2 的整数并输出。选择哪一个 case 取决于哪一个通道收到了信息。程序在 main 执行 1 秒后结束。
示例 14.10-goroutine_select.go:
1 | package main |
输出:
1 | Received on channel 2: 5 |
通道、超时和计时器(Ticker)
time 包中包含了 time.Ticker 结构体,这个对象以指定的时间间隔重复的向通道 C 发送时间值:
1 | type Ticker struct { |
时间间隔的单位是 ns(纳秒,int64),在工厂函数 time.NewTicker 中以 Duration 类型的参数传入:func Newticker(dur) *Ticker。
在协程周期性的执行一些事情(打印状态日志,输出,计算等等)的时候非常有用。
调用 Stop() 使计时器停止,在 defer 语句中使用。这些都很好的适应 select 语句:
1 | ticker := time.NewTicker(updateInterval) |
time.Tick() 函数声明为 Tick(d Duration) <-chan Time,当你想返回一个通道而不必关闭它的时候这个函数非常有用:它以 d 为周期给返回的通道发送时间,d是纳秒数。如果需要像下边的代码一样,限制处理频率(函数 client.Call() 是一个 RPC 调用,这里暂不赘述:
1 | import "time" |
这样只会按照指定频率处理请求:chRate 阻塞了更高的频率。每秒处理的频率可以根据机器负载(和/或)资源的情况而增加或减少。
定时器(Timer)结构体看上去和计时器(Ticker)结构体的确很像(构造为 NewTimer(d Duration)),但是它只发送一次时间,在 Dration d 之后。
还有 time.After(d) 函数,声明如下:
1 | func After(d Duration) <-chan Time |
在 Duration d 之后,当前时间被发到返回的通道;所以它和 NewTimer(d).C 是等价的;它类似 Tick(),但是 After() 只发送一次时间。下边有个很具体的示例,很好的阐明了 select 中 default 的作用:
示例 14.11:timer_goroutine.go):
1 | package main |
输出:
1 | . |
习惯用法:简单超时模式
要从通道 ch 中接收数据,但是最多等待1秒。先创建一个信号通道,然后启动一个 lambda 协程,协程在给通道发送数据之前是休眠的:
1 | timeout := make(chan bool, 1) |
然后使用 select 语句接收 ch 或者 timeout 的数据:如果 ch 在 1 秒内没有收到数据,就选择到了 time 分支并放弃了 ch 的读取。
1 | select { |
第二种形式:取消耗时很长的同步调用
也可以使用 time.After() 函数替换 timeout-channel。可以在 select 中通过 time.After() 发送的超时信号来停止协程的执行。以下代码,在 timeoutNs 纳秒后执行 select 的 timeout 分支后,执行client.Call 的协程也随之结束,不会给通道 ch 返回值:
1 | ch := make(chan error, 1) |
注意缓冲大小设置为 1 是必要的,可以避免协程死锁以及确保超时的通道可以被垃圾回收。此外,需要注意在有多个 case 符合条件时, select 对 case 的选择是伪随机的,如果上面的代码稍作修改如下,则 select 语句可能不会在定时器超时信号到来时立刻选中 time.After(timeoutNs) 对应的 case,因此协程可能不会严格按照定时器设置的时间结束。
1 | ch := make(chan int, 1) |
第三种形式:假设程序从多个复制的数据库同时读取。只需要一个答案,需要接收首先到达的答案,Query 函数获取数据库的连接切片并请求。并行请求每一个数据库并返回收到的第一个响应:
1 | func Query(conns []conn, query string) Result { |
再次声明,结果通道 ch 必须是带缓冲的:以保证第一个发送进来的数据有地方可以存放,确保放入的首个数据总会成功,所以第一个到达的值会被获取而与执行的顺序无关。正在执行的协程可以总是可以使用 runtime.Goexit() 来停止。
在应用中缓存数据:
应用程序中用到了来自数据库(或者常见的数据存储)的数据时,经常会把数据缓存到内存中,因为从数据库中获取数据的操作代价很高;如果数据库中的值不发生变化就没有问题。但是如果值有变化,我们需要一个机制来周期性的从数据库重新读取这些值:缓存的值就不可用(过期)了,而且我们也不希望用户看到陈旧的数据。
协程和恢复(recover)
一个用到 recover 的程序停掉了服务器内部一个失败的协程而不影响其他协程的工作。
1 | func server(workChan <-chan *Work) { |
上边的代码,如果 do(work) 发生 panic,错误会被记录且协程会退出并释放,而其他协程不受影响。
因为 recover 总是返回 nil,除非直接在 defer 修饰的函数中调用,defer 修饰的代码可以调用那些自身可以使用 panic 和 recover 避免失败的库例程(库函数)。举例,safelyDo() 中 defer 修饰的函数可能在调用 recover 之前就调用了一个 logging 函数,panicking 状态不会影响 logging 代码的运行。因为加入了恢复模式,函数 do(以及它调用的任何东西)可以通过调用 panic 来摆脱不好的情况。但是恢复是在 panicking 的协程内部的:不能被另外一个协程恢复。
新旧模型对比:任务和worker (锁vs协程)
假设我们需要处理很多任务;一个worker处理一项任务。任务可以被定义为一个结构体(具体的细节在这里并不重要):
1 | type Task struct { |
旧模式:使用共享内存进行同步
由各个任务组成的任务池共享内存;为了同步各个worker以及避免资源竞争,我们需要对任务池进行加锁保护:
1 | type Pool struct { |
sync.Mutex(是互斥锁:它用来在代码中保护临界区资源:同一时间只有一个go协程(goroutine)可以进入该临界区。如果出现了同一时间多个go协程都进入了该临界区,则会产生竞争:Pool结构就不能保证被正确更新。在传统的模式中(经典的面向对象的语言中应用得比较多,比如C++,JAVA,C#),worker代码可能这样写:
1 | func Worker(pool *Pool) { |
这些worker有许多都可以并发执行;他们可以在go协程中启动。一个worker先将pool锁定,从pool获取第一项任务,再解锁和处理任务。加锁保证了同一时间只有一个go协程可以进入到pool中:一项任务有且只能被赋予一个worker。如果不加锁,则工作协程可能会在task:=pool.Task[0]发生切换,导致pool.Tasks=pool.Task[1:]结果异常:一些worker获取不到任务,而一些任务可能被多个worker得到。加锁实现同步的方式在工作协程比较少时可以工作的很好,但是当工作协程数量很大,任务量也很多时,处理效率将会因为频繁的加锁/解锁开销而降低。当工作协程数增加到一个阈值时,程序效率会急剧下降,这就成为了瓶颈。
新模式:使用通道
使用通道进行同步:使用一个通道接受需要处理的任务,一个通道接受处理完成的任务(及其结果)。worker在协程中启动,其数量N应该根据任务数量进行调整。
主线程扮演着Master节点角色,可能写成如下形式:
1 | func main() { |
worker的逻辑比较简单:从pending通道拿任务,处理后将其放到done通道中:
1 | func Worker(in, out chan *Task) { |
这里并不使用锁:从通道得到新任务的过程没有任何竞争。随着任务数量增加,worker数量也应该相应增加,同时性能并不会像第一种方式那样下降明显。在pending通道中存在一份任务的拷贝,第一个worker从pending通道中获得第一个任务并进行处理,这里并不存在竞争(对一个通道读数据和写数据的整个过程是原子性的)。某一个任务会在哪一个worker中被执行是不可知的,反过来也是。worker数量的增多也会增加通信的开销,这会对性能有轻微的影响。
从这个简单的例子中可能很难看出第二种模式的优势,但含有复杂锁运用的程序不仅在编写上显得困难,也不容易编写正确,使用第二种模式的话,就无需考虑这么复杂的东西了。
因此,第二种模式对比第一种模式而言,不仅性能是一个主要优势,而且还有个更大的优势:代码显得更清晰、更优雅。一个更符合go语言习惯的worker写法:
IDIOM: Use an in- and out-channel instead of locking
1 | func Worker(in, out chan *Task) { |
对于任何可以建模为Master-Worker范例的问题,一个类似于worker使用通道进行通信和交互、Master进行整体协调的方案都能完美解决。如果系统部署在多台机器上,各个机器上执行Worker协程,Master和Worker之间使用netchan或者RPC进行通信(见下章)。
怎么选择是该使用锁还是通道?
通道是一个较新的概念,本节我们着重强调了在go协程里通道的使用,但这并不意味着经典的锁方法就不能使用。go语言让你可以根据实际问题进行选择:创建一个优雅、简单、可读性强、在大多数场景性能表现都能很好的方案。如果你的问题适合使用锁,也不要忌讳使用它。go语言注重实用,什么方式最能解决你的问题就用什么方式,而不是强迫你使用一种编码风格。下面列出一个普遍的经验法则:
使用锁的情景:
- 访问共享数据结构中的缓存信息
- 保存应用程序上下文和状态信息数据
使用通道的情景:
- 与异步操作的结果进行交互
- 分发任务
- 传递数据所有权
当你发现你的锁使用规则变得很复杂时,可以反省使用通道会不会使问题变得简单些。
惰性生成器的实现
生成器是指当被调用时返回一个序列中下一个值的函数,例如:
1 | generateInteger() => 0 |
生成器每次返回的是序列中下一个值而非整个序列;这种特性也称之为惰性求值:只在你需要时进行求值,同时保留相关变量资源(内存和cpu):这是一项在需要时对表达式进行求值的技术。例如,生成一个无限数量的偶数序列:要产生这样一个序列并且在一个一个的使用可能会很困难,而且内存会溢出!但是一个含有通道和go协程的函数能轻易实现这个需求。
在14.12的例子中,我们实现了一个使用 int 型通道来实现的生成器。通道被命名为yield和resume,这些词经常在协程代码中使用。
示例 14.12 lazy_evaluation.go:
1 | package main |
有一个细微的区别是从通道读取的值可能会是稍早前产生的,并不是在程序被调用时生成的。如果确实需要这样的行为,就得实现一个请求响应机制。当生成器生成数据的过程是计算密集型且各个结果的顺序并不重要时,那么就可以将生成器放入到go协程实现并行化。但是得小心,使用大量的go协程的开销可能会超过带来的性能增益。
这些原则可以概括为:通过巧妙地使用空接口、闭包和高阶函数,我们能实现一个通用的惰性生产器的工厂函数BuildLazyEvaluator(这个应该放在一个工具包中实现)。工厂函数需要一个函数和一个初始状态作为输入参数,返回一个无参、返回值是生成序列的函数。传入的函数需要计算出下一个返回值以及下一个状态参数。在工厂函数中,创建一个通道和无限循环的go协程。返回值被放到了该通道中,返回函数稍后被调用时从该通道中取得该返回值。每当取得一个值时,下一个值即被计算。在下面的例子中,定义了一个evenFunc函数,其是一个惰性生成函数:在main函数中,我们创建了前10个偶数,每个都是通过调用even()函数取得下一个值的。为此,我们需要在BuildLazyIntEvaluator函数中具体化我们的生成函数,然后我们能够基于此做出定义。
示例 14.13 general_lazy_evalution1.go:
1 | package main |
输出:
1 | 0th even: 0 |
实现 Futures 模式
所谓Futures就是指:有时候在你使用某一个值之前需要先对其进行计算。这种情况下,你就可以在另一个处理器上进行该值的计算,到使用时,该值就已经计算完毕了。
Futures模式通过闭包和通道可以很容易实现,类似于生成器,不同地方在于Futures需要返回一个值。
参考条目文献给出了一个很精彩的例子:假设我们有一个矩阵类型,我们需要计算两个矩阵A和B乘积的逆,首先我们通过函数Inverse(M)分别对其进行求逆运算,在将结果相乘。如下函数InverseProduct()实现了如上过程:
1 | func InverseProduct(a Matrix, b Matrix) { |
在这个例子中,a和b的求逆矩阵需要先被计算。那么为什么在计算b的逆矩阵时,需要等待a的逆计算完成呢?显然不必要,这两个求逆运算其实可以并行执行的。换句话说,调用Product函数只需要等到a_inv和b_inv的计算完成。如下代码实现了并行计算方式:
1 | func InverseProduct(a Matrix, b Matrix) { |
InverseFuture函数起了一个goroutine协程,在其执行闭包运算,该闭包会将矩阵求逆结果放入到future通道中:
1 | func InverseFuture(a Matrix) chan Matrix { |
当开发一个计算密集型库时,使用Futures模式设计API接口是很有意义的。在你的包使用Futures模式,且能保持友好的API接口。此外,Futures可以通过一个异步的API暴露出来。这样你可以以最小的成本将包中的并行计算移到用户代码中。(参见参考文件18:http://www.golangpatterns.info/concurrency/futures)
网络,模板和网页应用
go在编写web应用方面非常得力。因为目前它还没有GUI(Graphic User Interface 即图形化用户界面)的框架,通过文本或者模板展现的html界面是目前go编写应用程序的唯一方式。(**译者注:实际上在翻译的时候,已经有了一些不太成熟的GUI库例如:go ui。)
tcp服务器
这部分我们将使用TCP协议和在14章讲到的协程范式编写一个简单的客户端-服务器应用,一个(web)服务器应用需要响应众多客户端的并发请求:go会为每一个客户端产生一个协程用来处理请求。我们需要使用net包中网络通信的功能。它包含了用于TCP/IP以及UDP协议、域名解析等方法。
服务器代码,单独的一个文件:
示例 15.1 server.go
1 | package main |
我们在main()创建了一个net.Listener的变量,他是一个服务器的基本函数:用来监听和接收来自客户端的请求(来自localhost即IP地址为127.0.0.1端口为50000基于TCP协议)。这个Listen()函数可以返回一个error类型的错误变量。用一个无限for循环的listener.Accept()来等待客户端的请求。客户端的请求将产生一个net.Conn类型的连接变量。然后一个独立的协程使用这个连接执行doServerStuff(),开始使用一个512字节的缓冲data来读取客户端发送来的数据并且把它们打印到服务器的终端,len获取客户端发送的数据字节数;当客户端发送的所有数据都被读取完成时,协程就结束了。这段程序会为每一个客户端连接创建一个独立的协程。必须先运行服务器代码,再运行客户端代码。
客户端代码写在另外一个文件client.go中:
示例 15.2 client.go
1 | package main |
客户端通过net.Dial创建了一个和服务器之间的连接
它通过无限循环中的os.Stdin接收来自键盘的输入直到输入了“Q”。注意使用\r和\n换行符分割字符串(在windows平台下使用\r\n)。接下来分割后的输入通过connection的Write方法被发送到服务器。
当然,服务器必须先启动好,如果服务器并未开始监听,客户端是无法成功连接的。
如果在服务器没有开始监听的情况下运行客户端程序,客户端会停止并打印出以下错误信息:对tcp 127.0.0.1:50000发起连接时产生错误:由于目标计算机的积极拒绝而无法创建连接。
打开控制台并转到服务器和客户端可执行程序所在的目录,Windows系统下输入server.exe(或者只输入server),Linux系统下输入./server。
接下来控制台出现以下信息:Starting the server ...
在Windows系统中,我们可以通过CTRL/C停止程序。
然后开启2个或者3个独立的控制台窗口,然后分别输入client回车启动客户端程序
以下是服务器的输出:
1 | Starting the Server ... |
当客户端输入 Q 并结束程序时,服务器会输出以下信息:
1 | Error reading WSARecv tcp 127.0.0.1:50000: The specified network name is no longer available. |
在网络编程中net.Dial函数是非常重要的,一旦你连接到远程系统,就会返回一个Conn类型接口,我们可以用它发送和接收数据。Dial函数巧妙的抽象了网络结构及传输。所以IPv4或者IPv6,TCP或者UDP都可以使用这个公用接口。
下边这个示例先使用TCP协议连接远程80端口,然后使用UDP协议连接,最后使用TCP协议连接IPv6类型的地址:
示例 15.3 dial.go
1 | // make a connection with www.example.org: |
下边也是一个使用net包从socket中打开,写入,读取数据的例子:
示例 15.4 socket.go
1 | package main |
一个简单的网页服务器
Http是一个比tcp更高级的协议,它描述了客户端浏览器如何与网页服务器进行通信。Go有自己的net/http包,我们来看看它。我们从一些简单的示例开始,
首先编写一个“Hello world!”:查看示例15.6
我们引入了http包并启动了网页服务器,和15.1的net.Listen("tcp", "localhost:50000")函数的tcp服务器是类似的,使用http.ListenAndServe("localhost:8080", nil)函数,如果成功会返回空,否则会返回一个错误(可以指定localhost为其他地址,8080是指定的端口号)
http.URL描述了web服务器的地址,内含存放了url字符串的Path属性;http.Request描述了客户端请求,内含一个URL属性
如果req请求是一个POST类型的html表单,“var1”就是html表单中一个输入属性的名称,然后用户输入的值就可以通过GO代码:req.FormValue("var1")获取到(请看章节15.4)。还有一种方法就是先执行request.ParseForm()然后再获取request.Form["var1"]的第一个返回参数,就像这样:
1 | var1, found := request.Form["var1"] |
第二个参数found就是true,如果var1并未出现在表单中,found就是false
表单属性实际上是一个map[string][]string类型。网页服务器返回了一个http.Response,它是通过http.ResponseWriter对象输出的,这个对象整合了HTTP服务器的返回结果;通过对它写入内容,我们就将数据发送给了HTTP客户端。
现在我们还需要编写网页服务器必须执行的程序,它是如何处理请求的呢。这是在http.HandleFunc函数中完成的,就是在这个例子中当根路径“/”(url地址是http://localhost:8080 )被请求的时候(或者这个服务器上的其他地址),HelloServer函数就被执行了。这个函数是http.HandlerFunc类型的,它们通常用使用Prehandler来命名,在前边加了一个Pref前缀。
http.HandleFunc注册了一个处理函数(这里是HelloServer)来处理对应/的请求。
/可以被替换为其他特定的url比如/create,/edit等等;你可以为每一个特定的url定义一个单独的处理函数。这个函数需要两个参数:第一个是ReponseWriter类型的w;第二个是请求req。程序向w写入了Hello和r.URL.Path[1:]组成的字符串后边的[1:]表示“创建一个从第一个字符到结尾的子切片”,用来丢弃掉路径开头的“/”,fmt.Fprintf()函数完成了本次写入(请看章节12.8);另外一种写法是io.WriteString(w, "hello, world!\n")
总结:第一个参数是请求的路径,第二个参数是处理这个路径请求的函数的引用。
示例 15.6 hello_world_webserver.go
1 | package main |
使用命令行启动程序,会打开一个命令窗口显示如下文字:
1 | Starting Process E:/Go/GoBoek/code_examples/chapter_14/hello_world_webserver.exe |
然后打开你的浏览器并输入url地址:http://localhost:8080/world,浏览器就会出现文字:Hello, world,网页服务器会响应你在:8080/后边输入的内容
使用fmt.Println在控制台打印状态,在每个handler被请求的时候,在他们内部打印日志会很有帮助
注:
1)前两行(没有错误处理代码)可以替换成以下写法:
1 | http.ListenAndServe(":8080", http.HandlerFunc(HelloServer)) |
2)fmt.Fprint和fmt.Fprintf都是用来写入http.ResponseWriter的不错的函数(他们实现了io.Writer)。
比如我们可以使用
1 | fmt.Fprintf(w, "<h1>%s<h1><div>%s</div>", title, body) |
来构建一个非常简单的网页并插入title和body的值
如果你需要更多复杂的替换,使用模板包(请看章节15.7)
3)如果你需要使用安全的https连接,使用http.ListenAndServeTLS()代替http.ListenAndServe()
4)http.HandleFunc("/", Hfunc)中的HFunc是一个处理函数,如下:
1 | func HFunc(w http.ResponseWriter, req *http.Request) { |
也可以使用这种方式:http.Handle("/", http.HandlerFunc(HFunc))
上边的HandlerFunc只是一个类型名称,它定义如下:
1 | type HandlerFunc func(ResponseWriter, *Request) |
它是一个可以把普通的函数当做HTTP处理器的适配器。如果f函数声明的合适,HandlerFunc(f)就是一个执行了f函数的处理器对象。
http.Handle的第二个参数也可以是T的一个obj对象:http.Handle("/", obj)给T提供了ServeHTTP方法,实现了http的Handler接口:
1 | func (obj *Typ) ServeHTTP(w http.ResponseWriter, req *http.Request) { |
这个用法在章节15.8类型Counter和Chan上使用过。只要实现了http.Handler,http包就可以处理任何HTTP请求。
访问并读取页面
在下边这个程序中,数组中的url都将被访问:会发送一个简单的http.Head()请求查看返回值;它的声明如下:func Head(url string) (r *Response, err error)
返回状态码会被打印出来。
示例 15.7 poll_url.go:
1 | package main |
输出为:
1 | http://www.google.com/ : 302 Found |
译者注 由于国内的网络环境现状,很有可能见到如下超时错误提示:
1 | Error: http://www.google.com/ Head http://www.google.com/: dial tcp 216.58.221.100:80: connectex: A connection attempt failed because the connected pa |
在下边的程序中我们使用http.Get()获取网页内容; Get的返回值res中的Body属性包含了网页内容,然后我们用ioutil.ReadAll把它读出来:
示例 15.8 http_fetch.go:
1 | package main |
当访问不存在的网站时,这里有一个CheckError输出错误的例子:
1 | 2011/09/30 11:24:15 Get: Get http://www.google.bex: dial tcp www.google.bex:80:GetHostByName: No such host is known. |
译者注 和上一个例子相似,你可以把google.com更换为一个国内可以顺畅访问的网址进行测试
在下边的程序中,我们获取一个twitter用户的状态,通过xml包将这个状态解析成为一个结构:
示例 15.9 twitter_status.go
1 | package main |
输出:
1 | status: Robot cars invade California, on orders from Google: Google has been testing self-driving cars ... http://bit.ly/cbtpUN http://retwt.me/97p<exit code="0" msg="process exited normally"/> |
译者注 和上边的示例相似,你可能无法获取到xml数据,另外由于go版本的更新,xml.Unmarshal函数的第一个参数需是[]byte类型,而无法传入Body。
我们会在章节15.4中用到http包中的其他重要的函数:
http.Redirect(w ResponseWriter, r *Request, url string, code int):这个函数会让浏览器重定向到url(是请求的url的相对路径)以及状态码。http.NotFound(w ResponseWriter, r *Request):这个函数将返回网页没有找到,HTTP 404错误。http.Error(w ResponseWriter, error string, code int):这个函数返回特定的错误信息和HTTP代码。- 另
http.Request对象的一个重要属性req:req.Method,这是一个包含GET或POST字符串,用来描述网页是以何种方式被请求的。
go为所有的HTTP状态码定义了常量,比如:
http.StatusContinue = 100
http.StatusOK = 200
http.StatusFound = 302
http.StatusBadRequest = 400
http.StatusUnauthorized = 401
http.StatusForbidden = 403
http.StatusNotFound = 404
http.StatusInternalServerError = 500你可以使用w.header().Set("Content-Type", "../..")设置头信息
比如在网页应用发送html字符串的时候,在输出之前执行w.Header().Set("Content-Type", "text/html")。
写一个简单的网页应用
下边的程序在端口8088上启动了一个网页服务器;SimpleServer会处理/test1url使它在浏览器输出hello world。FormServer会处理/test2url:如果url最初由浏览器请求,那么它就是一个GET请求,并且返回一个form常量,包含了简单的input表单,这个表单里有一个文本框和一个提交按钮。当在文本框输入一些东西并点击提交按钮的时候,会发起一个POST请求。FormServer中的代码用到了switch来区分两种情况。在POST情况下,使用request.FormValue("inp")通过文本框的name属性inp来获取内容,并写回浏览器页面。在控制台启动程序并在浏览器中打开urlhttp://localhost:8088/test2来测试这个程序:
示例 15.10 simple_webserver.go
1 | package main |
注:当使用字符串常量表示html文本的时候,包含<html><body></body></html>对于让浏览器识别它收到了一个html非常重要。
更安全的做法是在处理器中使用w.Header().Set("Content-Type", "text/html")在写入返回之前将header的content-type设置为text/html
content-type会让浏览器认为它可以使用函数http.DetectContentType([]byte(form))来处理收到的数据
常用资料
Go 关键字
25 个关键字
1
2
3
4
5break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var36 个预定义标识符
1
2
3
4
5
6
7
8
9
10内建常量: true false iota nil
内建类型: int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
内建函数: make len cap new append copy close delete
complex real imag
panic recover
文件读写参数
1 | func OpenFile(name string, flag int, perm FileMode) (*File, error) |